Алфавитный подход к определению количества информацииПри определении количества информации на основе уменьшения неопределенности наших знаний мы рассматриваем информацию с точки зрения содержания, ее понятности и новизны для человека. С этой точки зрения в опыте по бросанию монеты одинаковое количество информации содержится и в зрительном образе упавшей монеты, и в коротком сообщении «Орел», и в длинной фразе «Монета упала на поверхность земли той стороной вверх, на которой изображен орел».Однако при хранении и передаче информации с помощью технических устройств целесообразно отвлечься от содержания информации и рассматривать ее как последовательность знаков (букв, цифр, кодов цветов точек изображения и так далее).Набор символов знаковой системы (алфавит) можно рассматривать как различные возможные состояния (события). Тогда, если считать, что появление символов в сообщении равновероятно, по формуле (2.1) можно рассчитать, какое количество информации несет каждый символ.Так, в русском алфавите, если не использовать букву ё, количество событий (букв) будет равно 32. Тогда:32 = 2I, откуда I = 5 битов.Каждый символ несет 5 битов информации (его информационная емкость равна 5 битов). Количество информации в сообщении можно подсчитать, умножив количество информации, которое несет один символ, на количество символов.


V = 5 бит * 11 = 55 бит
Ответ: слово информатика содержит 55 бит информации
Другие вопросы из категории
Даны 3 действительных числа. Возвести в квадрат и напечатать те из них, значения которых неотрицательны. Если таковых нет, то напечатать сообщение.
С++
Фамилия Пол Матема¬тика Русский язык Хи¬мия Инфор¬матика Биоло¬гия
Аганян ж 82 56 46 32 70
Воронин м 43 62 45 74 23
Григорчук м 54 74 68 75 83
Роднина ж 71 63 56 82 79
Сергеенко ж 33 25 74 38 46
Черепанова ж 18 92 83 28 61
Сколько записей в этом фрагменте удовлетворяют условию
«Пол=’ж’ ИЛИ Математика + Информатика >120»?
Составить программу, которая определяет произведение цифр четырехзначного числа, введенного пользователем.
2)
Составить программу, которая по формулам для арифметической прогрессии находит сумму n первых элементов прогрессии и значения трех элементов с номерами (n–1), n и (n+1). Число n, первый элемент и разность прогрессии вводятся пользователем. Вывести значения элементов в форме таблицы, где первая строка – номер, а вторая – значение.
Читайте также
несёт сообщение о том, что встреча назначена на 15 число?
3)Какое количество информации несёт сообщение о том, что встреча назначена на 23 октября в 15:00
4)Какое количество информации несет в себе сообщение о том, что нужная вам программа находится на одной из восьми дискет?
5) Какое количество информации получит второй игрок при игре в крестики-нолики на поле 8×8, после первого хода первого игрока, играющего крестиками?
6) В рулетке общее количество лунок равно 128. Какое количество информации мы получаем в зрительном собщения об остановке шарика в одной из лунок?
7) Происходит выбор одной карты из колоды в 32 карты. Какое количество информации мы получаем в зрительном сообщении о выборе определенной карты?
алфавита, содержит 20 символов. Какой объём информации оно несет?
содержат 5 страниц текста?
2. На предприятии имеется 9 автомобилей ГАЗ, 1 автомобилей ЗИЛ, 9 автомобилей КаМАЗ, 4 автомобилей MAN. Какое количество информации несет сообщение о выезде с территории автомобиля каждого вида?
2.Какова длина слова, если при словарном запасе в 256 слов одинаковой длины каждая буква алфавита несет в себе 2 бита информации?
1.Какова мощность алфавита, с помощью которого записано сообщение,
содержащее 2048 символов, если его объем составляет 1/512 часть
мегабайта?
2.система оптического распознавания текстов позволяет преобразовывать
отсканированные страницы документа в тест со скоростью 4 страницы в
минуту и использует алфавит мощностью 65536 символов. Какое количество
информации будет нести тестовый документ после 5 минут работ, если
каждая страница содержит 40 строк по 50 символов?
Измерение информации. меры информации. подходы к определению количества информации.
Люди обмениваются информацией в форме сообщений. Сообщение — это форма представления информации в виде речи, текстов, жестов, взглядов, изображений, цифровых данных, графиков, таблиц и т.п.
Одно и то же информационное сообщение (статья в газете, объявление, письмо, телеграмма, справка, рассказ, чертёж, радиопередача и т.п.) может содержать разное количество информации для разных людей — в зависимости от их предшествующих знаний, от уровня понимания этого сообщения и интереса к нему.
В информатике используются различные подходы к измерению информации:
Содержательный подход к измерению информации. Сообщение – информативный поток, который в процессе передачи информации поступает к приемнику. Сообщение несет информацию для человека, если содержащиеся в нем сведения являются для него новыми и понятными Информация — знания человека ? сообщение должно быть информативно. Если сообщение не информативно, то количество информации с точки зрения человека = 0. (Пример: вузовский учебник по высшей математике содержит знания, но они не доступны 1-класснику)
Алфавитный подход к измерению информации не связывает кол-во информации с содержанием сообщения. Алфавитный подход — объективный подход к измерению информации. Он удобен при использовании технических средств работы с информацией, т.к. не зависит от содержания сообщения. Кол-во информации зависит от объема текста и мощности алфавита. Ограничений на max мощность алфавита нет, но есть достаточный алфавит мощностью 256 символов. Этот алфавит используется для представления текстов в компьютере. Поскольку 256=28, то 1символ несет в тексте 8 бит информации.
Алфавит — упорядоченный набор символов, используемый для кодирования сообщений на некотором языке.
Мощность алфавита — количество символов алфавита.
Двоичный алфавит содержит 2 символа, его мощность равна двум.
Сообщения, записанные с помощью символов ASCII, используют алфавит из 256 символов. Сообщения, записанные по системе UNICODE, используют алфавит из 65 536 символов.
Вероятностный подход к измерения информации. Все события происходят с различной вероятностью, но зависимость между вероятностью событий и количеством информации, полученной при совершении того или иного события можно выразить формулой которую в 1948 году предложил Шеннон.
В вычислительной технике применяются две стандартные единицы измерения: бит (binary digit) и байт (byte). Если сообщение уменьшило неопределеность знаний ровно в два раза, то говорят, что сообщение несет 1 бит информации.
1 бит — объем информации такого сообщения, которое уменьшает неопределенность знания в два раза.
Для измерения информации используется и более крупные единицы:
| Единицы измерения информации в вычислительной технике | ||
| 1 бит | ||
| 1 байт | 8 бит | |
| 1 Кбайт (килобайт) | 210 байт = 1024 байт | 1 тыс. байт |
| 1 Мбайт (мегабайт) | 210 Кбайт = 220 байт | 1 млн. байт |
| 1 Гбайт (гигабайт) | 210 Мбайт = 230 байт | 1 млрд. байт |
| Количество информации – число, адекватно характеризующее разнообразие (структурированность, определенность, выбор состояний и т.д.) в оцениваемой системе. Количество информации часто оценивается в битах, причем такая оценка может выражаться и в долях бит (так речь идет не об измерении или кодировании сообщений). |
В настоящее время получили распространение подходы к определению понятия количество информации, основанные на том, что информацию, содержащуюся в сообщении, можно нестрого трактовать в смысле её новизны или, иначе, уменьшения неопределённости наших знаний об объекте. Эти подходы используют математические понятия вероятностии логарифма.
Мера информации – критерий оценки количества информации. Обычно она задана некоторой неотрицательной функцией, определенной на множестве событий и являющейся аддитивной, то есть мера конечного объединения событий (множеств) равна сумме мер каждого события.
| Подходы к определению количества информации.Формулы Хартли и Шеннона.Американский инженер Р. Хартли в 1928 г. процесс получения информации рассматривал как выбор одного сообщения из конечного наперёд заданного множества из N равновероятных сообщений, а количество информации I, содержащееся в выбранном сообщении, определял как двоичный логарифм N. |
| Формула Хартли: I = log2N |
Допустим, нужно угадать одно число из набора чисел от единицы до ста. По формуле Хартли можно вычислить, какое количество информации для этого требуется: I = log2100 6,644. Таким образом, сообщение о верно угаданном числе содержит количество информации, приблизительно равное 6,644 единицы информации.
Приведем другие примеры равновероятных сообщений:
- при бросании монеты: выпала решка, выпал орел;
- на странице книги: количество букв чётное, количество букв нечётное.
Определим теперь, являются ли равновероятными сообщения первой выйдет из дверей здания женщина и первым выйдет из дверей здания мужчина. Однозначно ответить на этот вопрос нельзя. Все зависит от того, о каком именно здании идет речь. Если это, например, станция метро, то вероятность выйти из дверей первым одинакова для мужчины и женщины, а если это военная казарма, то для мужчины эта вероятность значительно выше, чем для женщины.
Для задач такого рода американский учёный Клод Шеннон предложил в 1948 г. другую формулу определения количества информации, учитывающую возможную неодинаковую вероятность сообщений в наборе.
| Формула Шеннона: I = — ( p1log2 p1 + p2 log2 p2 + . . . + pN log2 pN), где pi — вероятность того, что именно i-е сообщение выделено в наборе из N сообщений. |
Легко заметить, что если вероятности p1, …, pN равны, то каждая из них равна 1 / N, и формула Шеннона превращается в формулу Хартли.
Помимо двух рассмотренных подходов к определению количества информации, существуют и другие. Важно помнить, что любые теоретические результаты применимы лишь к определённому кругу случаев, очерченному первоначальными допущениями.
В качестве единицы информации Клод Шеннон предложил принять один бит (англ. bit — binary digit — двоичная цифра).
| Бит в теории информации — количество информации, необходимое для различения двух равновероятных сообщений (типа орел—решка, чет—нечет и т.п.). В вычислительной технике битом называют наименьшую порцию памяти компьютера, необходимую для хранения одного из двух знаков 0 и 1, используемых для внутримашинного представления данных и команд. |
Бит — слишком мелкая единица измерения. На практике чаще применяется более крупная единица — байт, равная восьми битам. Именно восемь битов требуется для того, чтобы закодировать любой из 256 символов алфавита клавиатуры компьютера (256=28).
Широко используются также ещё более крупные производные единицы информации:
| 1 Килобайт (Кбайт) = 1024 байт = 210 байт, | |
| 1 Мегабайт (Мбайт) = 1024 Кбайт = 220 байт, | |
| 1 Гигабайт (Гбайт) = 1024 Мбайт = 230 байт. |
В последнее время в связи с увеличением объёмов обрабатываемой информации входят в употребление такие производные единицы, как:
| 1 Терабайт (Тбайт) = 1024 Гбайт = 240 байт, | |
| 1 Петабайт (Пбайт) = 1024 Тбайт = 250 байт. |
Информационный объем сообщения (информационная емкость сообщения) – количество информации в сообщении, измеренное в битах, байтах или производных единицах (Кбайтах, Мбайтах и т. д.).
Статьи к прочтению:
Информация, количество информации
Похожие статьи:
Лабораторная работа №1 «Измерение информации» В информатике используются различные подходы к измерению информации: Количество информации- это мера…
Количество информации как мера уменьшения неопределенности знания Получение информации можно связать с уменьшением неопределенности знания. Это позволяет…
Количество информации
Урок 5. Информатика 8 класс
Конспект урока «Количество информации»
Процесс познания приводит к накоплению информации (знаний), то есть к уменьшению неопределенности знания.

Измерить объём накопленных знаний нельзя, а вот оценить уменьшение незнания можно, если известно количество возможных вариантов исхода.
Количество информации — мера уменьшения неопределённости знаний при получении информационных сообщений.
Существует формула, которая связывает между собой количество возможных информационных сообщений N и количество информации I, которое несёт полученное сообщение:
 — формула Хартли,
— формула Хартли,
где N — количество вариантов исхода;
I — количество информации, которое несёт сообщение.
В своей деятельности человек постоянно использует различные единицы измерения. Например, время измеряется в секундах, минутах, часах; расстояние — в метрах, километрах; температура — в градусах и т.д.

Для измерения количества информации тоже существуют свои единицы. Минимальную единицу количества информации называют битом.
Давайте рассмотрим примеры:
1. При бросании монеты возможны два варианта исхода (орёл или решка). Заранее не известен результат, мы имеем некоторую неопределённость. После падения монеты виден один вариант вместо двух (неопределённость исчезла).

2. До проверки контрольной работы учителем возможны четыре вариант исхода («2», «3», «4», «5»). После получения оценки остался один вариант (неопределённость исчезла).

Рассмотренные примеры позволяют сделать вывод: чем больше неопределённости первоначальной ситуации (чем больше вариантов исхода), тем больше количество информации содержится в сообщении, снимающем эту неопределённость.
1 бит — это количество информации в сообщении, которое уменьшает неопределённость в 2 раза.
Следующей по величине единицей является байт. Байт — это единица измерения количества информации, состоящая из восьми последовательных и взаимосвязанных битов.

Т.к. в компьютере информация кодируется с помощью двоичной знаковой системы, поэтому в кратных единицах измерения количества информации используется коэффициент 2 n .
Существуют кратные байту единицы измерения количества информации:
1 килобайт (Кбайт) = 2 10 байтов = 1024 байтов;
1 мегабайт (Мбайт) = 2 10 Кбайт = 1024 Кбайт;
1 гигабайт (Гбайт) = 2 10 Мбайт = 1024 Мбайт.
В этих единицах измеряются объемы памяти компьютера, размеры файлов.
На экзамене вы берете экзаменационный билет, и учитель сообщает вам, что зрительное информационное сообщение о его номере несет 5 битов информации. Определите количество экзаменационных билетов.
Для того чтобы определить количество экзаменационных билетов, достаточно определить количество возможных информационных сообщений об их номерах. Для этого воспользуемся формулой Хартли:

Таким образом, количество экзаменационных билетов равно 32.
Представьте себе, что вы управляете движением робота и можете задавать направление его движения с помощью информационных сообщений: «север», «северо-восток», «восток», «юго-восток», «юг», «юго-запад», «запад» и «северо-запад». Какое количество информации будет получать робот после каждого сообщения?

Исходя из условия задачи всего возможных информационных сообщений 8, т.е. N=8. Тогда, воспользовавшись формулой Хартли, мы получим:

Разложим стоящее в левой части уравнения число 8 на сомножители и представим его в степенной форме:

Итак, мы получили:
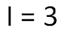
Равенство левой и правой частей уравнения справедливо, если равны показатели степени числа 2. Таким образом, I = 3 бита, т. е. количество информации, которое несет роботу каждое информационное сообщение, равно 3 битам.
Определение количества информации. Алфавитный подход. ЕГЭ
ЕГЭ Определениеколичестваинформации( ) алфавитныйподход( ) алфавитныйподход Урок 3 При хранении и передаче информации с помощью технических устройств информация рассматривается как последовательность символов – знаков (букв, цифр, кодов цветов точек изображения и т.д.) Набор символов знаковой системы (алфавит) можно рассматривать как различные возможные состояния (события).
Тогда, если считать, что появление символов в сообщении равновероятно, по формулеN = 2I можно рассчитать, какое количество информации несет каждый символ.
Информационная емкость знаков зависит от их количества в алфавите.
Так, информационная емкость буквы в русском алфавите, если не использовать букву «ё», составляет: 32 = 2I , т.е.I = 5 битов На основании алфавитного подхода можно подсчитать количество информации в сообщенииIc , для этого необходимо умножить количество информации, которое несет один символI , на количество символовK в сообщении:Ic =I× K Решение задач 1.
Какое количество информации (с точки зрения алфавитного подхода) содержит слово « экзамен », если считать, что алфавит состоит из 32 букв? Решение: В слове «экзамен» 7 букв (K =7).
Информационная емкость буквы в русском алфавите составляет: 32 = 2I , т.е.I = 5 битов.
Умножим количество информации, которое несет один символI , на количество символовK в сообщении:Ic = I× KIc = 5× 7 = 35 битов.
Ответ: 35 битов 2.
Какое количество информации (с точки зрения алфавитного похода) содержит двоичное число 1012? 1) 3 байта 2) 2 байта 3) 3 бита 4) 2 бита Решение: Каждая1 или0 – это 1 бит.
Какое количество информации (с точки зрения алфавитного подхода) содержит восьмеричное число 558? 1) 10 битов 2) 8 битов 3) 6 битов 4) 5 битов Решение: Восьмеричная система счисления кодирует информацию с помощью восьми символов (0 – 7).N = 2I , 8 = 2I , т.к.
8=23 , то 23 = 2I,I = 3Ic =I× K, количество символовK=2Ic = 3× 2 = 6 битов.
Ответ: 6 битов 4.
Какое количество информации (с точки зрения алфавитного похода) содержит шестнадцатеричное число AB16? 1) 16 битов 2) 8 битов 3) 4 бита 4) 2 бита Решение: Шестнадцатеричная система счисления кодирует информацию с помощью шестнадцати символов (0 – 9,A –F).N = 2I , 16 = 2I , т.к.
16=24 , то 24 = 2I,I = 4Ic =I× K, количество символовK=2Ic = 4× 2 = 8 битов.
Ответ: 8 битов 5.
Датчик должен фиксировать в памяти электронного устройства 30 различных сигналов, которые закодированы двоичным кодом минимальной длины.
Записано 160 показаний этого датчика.
Каков информационный объем снятых значений? 1) 600 байт 2) 4 800 байт 3) 100 байт 4) 800 байт РешениеN = 2I2I = 32,I = 5 (минимальная длина кода)160 показаний * 5 = 800 бит 800 бит / 8 = 100 байт Ответ:1006.
Система оптического распознавания символов позволяет преобразовывать отсканированные изображения страниц документа в текстовый формат со скоростью4 страницы в минуту и использует алфавит мощностью 65 536 символов.
Какое количество информации будет нести текстовый документ, каждая страница которого содержит40 строк по50 символов, после10 минут работы приложения? Решение: Информационная емкость 1 символа алфавита:N = 2I , 65 536 = 2I,216 = 2I, I = 16 битов Количество информации на странице: 16 битов * 40 * 50 =32 000 битов 1 байт = 8 бит, 32 000 битов/ 8 = 4 000 байтов Количество информации, которое будет нести текстовый документ: 4 000 байтов * 4 * 10 = 160 000 байтов≈ 156 Кбайт Ответ:156 Домашняя работа №3 (задания из ЕГЭ!) 1.
Какое количество информации (с точки зрения алфавитного похода) содержит двоичное число 1002? 2.
Какое количество информации (с точки зрения алфавитного подхода) содержит восьмеричное число 7778? 3.
Какое количество информации (с точки зрения алфавитного похода) содержит шестнадцатеричное числоABC16? 4.
Какое количество информации (с точки зрения алфавитного похода) содержит слово «информатика»? 5.
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объем следующего высказывания Блеза Паскаля: Красноречие – это живопись мысли.
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объем следующего высказывания Оноре де Бальзака: Ключом ко всякой науке является вопросительный знак.
Электронное устройство приемника должно принимать и воспроизводить 14 различных сигналов, которые закодированы двоичным кодом минимальной длины.
Сколько сигналов приняло устройство, если объем данного информационного сообщения 40 байт? 8.
Электронное устройство приемника должно принимать и воспроизводить 6 различных сигналов, которые закодированы двоичным кодом минимальной длины.
Устройство приняло 160 сигналов.
Каков объем данного сообщения в байтах? 9.
Электронное устройство приемника должно принимать и воспроизводить 11 различных сигналов, которые закодированы двоичным кодом минимальной длины.
Сколько сигналов приняло устройство, если объем данного информационного сообщения 100 байт? 10.
Для передачи секретного сообщения используется код, состоящий из 26 латинских букв.
При этом все буквы кодируются одним и тем же (минимально возможным) количеством бит.
Определите информационный объем сообщения длиной в 120 символов в байтах.
Электронное устройство приемника должно принимать и воспроизводить 9 различных сигналов, которые закодированы двоичным кодом минимальной длины.
5. Количество информации. Измерение информации. Единицы измерения
За единицу количества информации принимается такое количество информации, которое содержит сообщение, уменьшающее неопределенность в два раза. Такая единица названа «бит».
Для информации существуют свои единицы измерения информации. Если рассматривать сообщения информации как последовательность знаков, то их можно представлять битами, а измерять в байтах, килобайтах, мегабайтах, гигабайтах, терабайтах и петабайтах.
Давайте разберемся с этим, ведь нам придется измерять объем памяти и быстродействие компьютера.
Единицей измерения количества информации является бит – это наименьшая (элементарная) единица.
1бит – это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Байт – основная единица измерения количества информации.
Байтом называется последовательность из 8 битов.
Байт – довольно мелкая единица измерения информации. Например, 1 символ – это 1 байт.
Производные единицы измерения количества информации
1 килобайт (Кб)=1024 байта =210 байтов
1 мегабайт (Мб)=1024 килобайта =210 килобайтов=220 байтов
1 гигабайт (Гб)=1024 мегабайта =210 мегабайтов=230 байтов
1 терабайт (Гб)=1024 гигабайта =210 гигабайтов=240 байтов
Запомните, приставка КИЛО в информатике – это не 1000, а 1024, то есть 210 .
Методы измерения количества информации
Итак, количество информации в 1 бит вдвое уменьшает неопределенность знаний. Связь же между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Алфавитный подход к измерению количества информации
При этом подходе отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка, т.е. его алфавит можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет в себе каждый символ:
Вероятностный подход к измерению количества информации
Этот подход применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
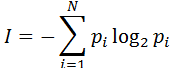 , где
, где
I – количество информации,
N – количество возможных событий,
Pi – вероятность i-го события.
6. Кодирование информации различных видов
1.6.1. КОДИРОВАНИЕ ЧИСЕЛ.
Используя n бит, можно записывать двоичные коды чисел от 0 до 2n-1, всего 2n чисел.
1) Кодирование положительных чисел: Для записи положительных чисел в байте заданное число слева дополняют нулями до восьми цифр. Эти нули называют незначимыми.
Например: записать в байте число 1310 = 11012
2) Кодирование отрицательных чисел:Наибольшее положительное число, которое можно записать в байт, — это 127, поэтому для записи отрицательных чисел используют числа с 128-го по 255-е. В этом случае, чтобы записать отрицательное число, к нему добавляют 256, и полученное число записывают в ячейку.
1.6.2. КОДИРОВАНИЕ ТЕКСТА.
Соответствие между набором букв и числами называется кодировкой символа. Как правило, код символа хранится в одном байте, поэтому коды символов могут принимать значение от 0 до 255. Такие кодировки называют однобайтными. Они позволяют использовать 256 символов. Таблица кодов символов называется ASCII (American StandardCodeforInformationInterchange- Американский стандартный код для обмена информацией). Таблица ASCII-кодов состоит из двух частей:
Коды от 0 до 127 одинаковы для всех IBM-PC совместимых компьютеров и содержат:
коды управляющих символов;
коды цифр, арифметических операций, знаков препинания;
некоторые специальные символы;
коды больших и маленьких латинских букв.
Вторая часть таблицы (коды от 128 до 255) бывает различной в различных компьютерах. Она содержит:
коды букв национального алфавита;
коды некоторых математическихсимволов;
коды символов псевдографики.
В настоящее время все большее распространение приобретает двухбайтная кодировка Unicode. В ней коды символов могут принимать значение от 0 до 65535.
1.6.3. КОДИРОВАНИЕ ЦВЕТОВОЙ ИНФОРМАЦИИ.
Одним байтом можно закодировать 256 различных цветов. Это достаточно для рисованных изображений типа мультфильмов, но не достаточно для полноцветных изображений живой природы. Если для кодирования цвета использовать 2 байта, можно закодировать уже 65536 цветов. А если 3 байта – 16,5 млн. различных цветов. Такой режим позволяет хранить, обрабатывать и передавать изображения, не уступающие по качеству наблюдаемым в живой природе.
Из курса физики известно, что любой цвет можно представить в виде комбинации трех основных цветов: красного, зеленого, синего (их называют цветовыми составляющими). Если кодировать цвет точки с помощью 3 байтов, то первый байт выделяется красной составляющей, второй – зеленой, третий – синей. Чем больше значение байта цветовой составляющей, тем ярче этот цвет.
Белый цвет – у точки есть все цветовые составляющие, и они имеют полную яркость. Поэтому белый цвет кодируется так: 255 255 255. (11111111 11111111 11111111)
Черный цвет – отсутствие всех прочих цветов: 0 0 0. (00000000 00000000 00000000)
Серый цвет – промежуточный между черным и белым. В нем есть все цветовые составляющие, но они одинаковы и нейтрализуют друг друга.
Например: 100 100 100 или 150 150 150. (2-й вариант — ярче).
Красный цвет – все составляющие, кроме красной, равны 0. Темно-красный: 128 0 0. Ярко-красный: 255 0 0.
Зеленый цвет – 0 255 0.
Синий цвет – 0 0 255.
1.6.4. КОДИРОВАНИЕ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ.
Рисунок разбивают на точки. Чем больше будет точек, и чем мельче они будут, тем точнее будет передача рисунка. Затем, двигаясь по строкам слева направо начиная с верхнего левого угла, последовательно кодируют цвет каждой точки. Для черно-белой картинки достаточно 1 байта для точки, для цветной – до 3-х байт для одной точки.
Двоичная система счисления
В двоичной системе счисления используются всего две цифры 0 и 1. Другими словами, двойка является основанием двоичной системы счисления. (Аналогично у десятичной системы основание 10.)
Чтобы научиться понимать числа в двоичной системе счисления, сначала рассмотрим, как формируются числа в привычной для нас десятичной системе счисления.
В десятичной системе счисления мы располагаем десятью знаками-цифрами (от 0 до 9). Когда счет достигает 9, то вводится новый разряд (десятки), а единицы обнуляются и счет начинается снова. После 19 разряд десятков увеличивается на 1, а единицы снова обнуляются. И так далее. Когда десятки доходят до 9, то потом появляется третий разряд – сотни.
Двоичная система счисления аналогична десятичной за исключением того, что в формировании числа участвуют всего лишь две знака-цифры: 0 и 1. Как только разряд достигает своего предела (т.е. единицы), появляется новый разряд, а старый обнуляется.
Попробуем считать в двоичной системе:
1 – это один (и это предел разряда)
11 – это три (и это снова предел)
100 – это четыре
Перевод чисел из двоичной системы счисления в десятичную
Не трудно заметить, что в двоичной системе счисления длины чисел с увеличением значения растут быстрыми темпами. Как определить, что значит вот это: 10001001? Непривычный к такой форме записи чисел человеческий мозг обычно не может понять сколько это. Неплохо бы уметь переводить двоичные числа в десятичные.
В десятичной системе счисления любое число можно представить в форме суммы единиц, десяток, сотен и т.д. Например:
1476 = 1000 + 400 + 70 + 6
Можно пойти еще дальше и разложить так:
1476 = 1 * 103 + 4 * 102 + 7 * 101 + 6 * 100
Посмотрите на эту запись внимательно. Здесь цифры 1, 4, 7 и 6 — это набор цифр из которых состоит число 1476. Все эти цифры поочередно умножаются на десять возведенную в ту или иную степень. Десять – это основание десятичной системы счисления. Степень, в которую возводится десятка – это разряд цифры за минусом единицы.
Аналогично можно разложить и любое двоичное число. Только основание здесь будет 2:
10001001 = 1*27 + 0*26 + 0*25 + 0*24 + 1*23 + 0*22 + 0*21 + 1*20
Если посчитать сумму составляющих, то в итоге мы получим десятичное число, соответствующее 10001001:
1*27 + 0*26 + 0*25 + 0*24 + 1*23 + 0*22 + 0*21 + 1*20 = 128 + 0 + 0 + 0 + 8 + 0 + 0 + 1 = 137
Т.е. число 10001001 по основанию 2 равно числу 137 по основанию 10. Записать это можно так:
Почему двоичная система счисления так распространена?
Дело в том, что двоичная система счисления – это язык вычислительной техники. Каждая цифра должна быть как-то представлена на физическом носителе. Если это десятичная система, то придется создать такое устройство, которое может быть в десяти состояниях. Это сложно. Проще изготовить физический элемент, который может быть лишь в двух состояниях (например, есть ток или нет тока). Это одна из основных причин, почему двоичной системе счисления уделяется столько внимания.
Перевод десятичного числа в двоичное
Может потребоваться перевести десятичное число в двоичное. Один из способов – это деление на два и формирование двоичного числа из остатков. Например, нужно получить из числа 77 его двоичную запись:
77 / 2 = 38 (1 остаток)
38 / 2 = 19 (0 остаток)
19 / 2 = 9 (1 остаток)
9 / 2 = 4 (1 остаток)
4 / 2 = 2 (0 остаток)
2 / 2 = 1 (0 остаток)
1 / 2 = 0 (1 остаток)
Собираем остатки вместе, начиная с конца: 1001101. Это и есть число 77 в двоичном представлении. Проверим:
1001101 = 1*26 + 0*25 + 0*24 + 1*23 + 1*22 + 0*21 + 1*20 = 64 + 0 + 0 + 8 + 4 + 0 + 1 = 77
ASCII(англ. American Standard Code for Information Interchange) — американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов. В американском варианте английского языка произносится [э́ски], тогда как в Великобритании чаще произносится [а́ски]; по-русски произносится также [а́ски] или [аски́].
ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. Изначально разработанная как 7-битная, с широким распространением 8-битного байта ASCII стала восприниматься как половина 8-битной. В компьютерах обычно используют расширения ASCII с задействованным 8-м битом и второй половиной кодовой таблицы (например КОИ-8).
Поскольку ASCII изначально предназначался для обмена информацией (по телетайпу), в нём, кроме информационных символов, используются символы-команды для управления связью. Это обычный набор спецсигналов, применявшийся и в других докомпьютерных средствах обмена сообщениями (азбука Морзе, семафорная азбука), дополненный с учётом специфики устройства.
(После названия каждого символа указан его 16-ричный код)
NUL, 00 — Null, пустой. Всегда игнорировался. На перфолентах 1 представлялась отверстием, 0 — отсутствием отверстия. Поэтому пустые части перфоленты до начала и после конца сообщения состояли из таких символов. Сейчас используется во многих языках программирования как конец строки. (Строка понимается как последовательность символов.) В некоторых операционных системах NUL — последний символ любого текстового файла.
SOH, 01 — Start Of Heading, начало заголовка.
STX, 02 — Start of Text, начало текста. Текстом называлась часть сообщения, предназначенная для печати. Адрес, контрольная сумма и т. д. входили или в заголовок, или в часть сообщения после текста.
ETX, 03 — End of Text, конец текста. Здесь телетайп прекращал печатать. Использование символа Ctrl-C, имеющего код 03, для прекращения работы чего-то (обычно программы), восходит ещё к тем временам.
EOT, 04 — End of Transmission, конец передачи. В системе UNIX Ctrl-D, имеющий тот же код, означает конец файла при вводе с клавиатуры.
ENQ, 05 — Enquire. Прошу подтверждения.
ACK, 06 — Acknowledgement. Подтверждаю.
BEL, 07 — Bell, звонок, звуковой сигнал. Сейчас тоже используется. В языках программирования C и C++ обозначается \a.
BS, 08 — Backspace, возврат на один символ. Сейчас стирает предыдущий символ.
TAB, 09 — Tabulation. Обозначался также HT — Horizontal Tabulation, горизонтальная табуляция. Во многих языках программирования обозначается \t .
LF, 0A — Line Feed, перевод строки. Сейчас в конце каждой строчки текстового файла ставится либо этот символ, либо CR, либо и тот и другой (CR, затем LF), в зависимости от операционной системы. Во многих языках программирования обозначается \n и при выводе текста приводит к переводу строки.
VT, 0B — Vertical Tab, вертикальная табуляция.
FF, 0C — Form Feed, прогон страницы, новая страница.
CR, 0D — Carriage Return, возврат каретки. Во многих языках программирования этот символ, обозначаемый \r, можно использовать для возврата в начало строчки без перевода строки. В некоторых операционных системах этот же символ, обозначаемый Ctrl-M, ставится в конце каждой строчки текстового файла перед LF.
SO, 0E — Shift Out, измени цвет ленты (использовался для двуцветных лент; цвет менялся обычно на красный). В дальнейшем обозначал начало использования национальной кодировки.
SI, 0F — Shift In, обратно к Shift Out.
DLE, 10 — Data Link Escape, освобождение канала данных — следующие символы представляют собой данные, а не управляющие символы.
DC1, 11 — Device Control 1, 1-й символ управления устройством — включить устройство чтения перфоленты.
DC2, 12 — Device Control 2, 2-й символ управления устройством — включить перфоратор.
DC3, 13 — Device Control 3, 3-й символ управления устройством — выключить устройство чтения перфоленты.
DC4, 14 — Device Control 4, 4-й символ управления устройством — выключить перфоратор.
NAK, 15 — Negative Acknowledgment, не подтверждаю. Обратно Acknowledgment.
SYN, 16 — Synchronization. Этот символ передавался, когда для синхронизации было необходимо что-нибудь передать.
ETB, 17 — End of Text Block, конец текстового блока. Иногда текст по техническим причинам разбивался на блоки.
CAN, 18 — Cancel, отмена (того, что было передано ранее).
EM, 19 — End of Medium, конец носителя (кончилась перфолента и т. д.)
SUB, 1A — Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче. Сейчас Ctrl-Z используется как конец файла при вводе с клавиатуры в системах DOS и Windows. У этой функции нет никакой очевидной связи с символом SUB.
ESC, 1B — Escape. Следующие за ним символы имеют какое-то другое значение, отличное от того, которое определено в ASCII. Обычно начинал управляющие последовательности.
FS, 1C — File Separator, разделитель файлов.
GS, 1D — Group Separator, разделитель групп.
RS, 1E — Record Separator, разделитель записей.
US, 1F — Unit Separator, разделитель юнитов. То есть поддерживалось 4 уровня структуризации данных: сообщение могло состоять из файлов, файлы из групп, группы из записей, записи из юнитов.
DEL, 7F — Delete, стереть последний символ. Символом DEL, состоящим в двоичном коде из всех единиц, можно было забить любой символ. Устройства и программы игнорировали DEL так же, как NUL. Код этого символа происходит из первых текстовых процессоров с памятью на перфоленте: в них удаление символа происходило забиванием его кода дырочками (обозначавшими логические единицы).
Растровая и векторная графика
Способы представления изображений в памяти ЭВМ
Формальное определение компьютерная (машинная) графика – это создание, хранение и обработка моделей объектов и их изображений с помощью ЭВМ. Под интерактивной компьютерной графикой понимают раздел компьютерной графики, изучающий вопросы динамического управления со стороны пользователя содержанием изображения, его формой, размерами и цветом на экране с помощью интерактивных устройств взаимодействия.
Под компьютерной геометрией понимают математический аппарат, применяемый в компьютерной графике.
Необходимо отметить следующую отличительную черту компьютерных изображений. Изображения, которые мы встречаем в нашей повседневной жизни, реальные картины природы, можно бесконечно детализировать, выявлять все новые цвета и оттенки. Изображения, хранящиеся в памяти компьютера, независимо от способа их получения и представления, всегда являются усеченной моделью картины реального мира. Их детализация возможна лишь с той степенью, которая была заложена при их создании или получении, и их цветовая гамма будет не шире заранее оговоренной.
Одно и то же изображение может быть представлено в памяти ЭВМ двумя принципиально различными способами и получено два различных типа изображения: растровое и векторное. Рассмотрим подробнее эти способы представления изображений, выделим их основные параметры и определим их достоинства и недостатки.
Что такое растровое изображение?
Возьмём фотографию (например, см. рис. 1.1). Конечно, она тоже состоит из маленьких элементов, но будем считать, что отдельные элементы мы рассмотреть не можем. Она представляется для нас, как реальная картина природы.
Теперь разобьём это изображение на маленькие квадратики (маленькие, но всё-таки чётко различимые), и каждый квадратик закрасим цветом, преобладающим в нём (на самом деле программы при оцифровке генерируют некий «средний» цвет, т. е. если у нас была одна чёрная точка и одна белая, то квадратик будет иметь серый цвет).
Как мы видим, изображение стало состоять из конечного числа квадратиков определённого цвета. Эти квадратики называют pixel (от PICture ELement) – пиксел или пиксель.

Рис. 1.1. Исходное изображение
Теперь каким-либо методом занумеруем цвета. Конкретная реализация этих методов нас пока не интересует. Для нас сейчас важно то, что каждый пиксель на рисунке стал иметь определённый цвет, обозначенный цифрой (рис. 1.2).

Рис. 1.2. Фрагмент оцифрованного изображения и номера цветов
Теперь пойдём по порядку (слева направо и сверху вниз) и будем в строчку выписывать номера цветов встречающихся пикселей. Получится строка примерно следующего вида:
1 2 8 3 212 45 67 45 127 4 78 225 34 .
Вот эта строка и есть наши оцифрованные данные. Теперь мы можем сжать их (так как несжатые графические данные обычно имеют достаточно большой размер) и сохранить в файл.
Итак, под растровым (bitmap, raster) понимают способ представления изображения в виде совокупности отдельных точек (пикселей) различных цветов или оттенков. Это наиболее простой способ представления изображения, ибо таким образом видит наш глаз.
Достоинством такого способа является возможность получения фотореалистичного изображения высокого качества в различном цветовом диапазоне. Недостатком – высокая точность и широкий цветовой диапазон требуют увеличения объема файла для хранения изображения и оперативной памяти для его обработки.
Для векторной графики характерно разбиение изображения на ряд графических примитивов – точки, прямые, ломаные, дуги, полигоны. Таким образом, появляется возможность хранить не все точки изображения, а координаты узлов примитивов и их свойства (цвет, связь с другими узлами и т. д.).
Вернемся к изображению на рис. 1.1. Взглянем на него по-другому. На изображении легко можно выделить множество простых объектов — отрезки прямых, ломанные, эллипс, замкнутые кривые. Представим себе, что пространство рисунка существует в некоторой координатной системе. Тогда можно описать это изображение, как совокупность простых объектов, вышеперечисленных типов, координаты узлов которых заданы вектором относительно точки начала координат (рис. 1.3).

Рис. 1.3. Векторное изображение и узлы его примитивов
Проще говоря, чтобы компьютер нарисовал прямую, нужны координаты двух точек, которые связываются по кратчайшей прямой. Для дуги задается радиус и т. д. Таким образом, векторная иллюстрация – это набор геометрических примитивов.
Важной деталью является то, что объекты задаются независимо друг от друга и, следовательно, могут перекрываться между собой.
При использовании векторного представления изображение хранится в памяти как база данных описаний примитивов. Основные графические примитивы, используемые в векторных графических редакторах: точка, прямая, кривая Безье, эллипс (окружность), полигон (прямоугольник). Примитив строится вокруг его узлов (nodes). Координаты узлов задаются относительно координатной системы макета.
А изображение будет представлять из себя массив описаний – нечто типа:
Каждому узлу приписывается группа параметров, в зависимости от типа примитива, которые задают его геометрию относительно узла. Например, окружность задается одним узлом и одним параметром – радиусом. Такой набор параметров, которые играют роль коэффициентов и других величин в уравнениях и аналитических соотношениях объекта данного типа, называют аналитической моделью примитива. Отрисовать примитив – значит построить его геометрическую форму по его параметрам согласно его аналитической модели.
Векторное изображение может быть легко масштабировано без потери деталей, так как это требует пересчета сравнительно небольшого числа координат узлов. Другой термин – «object-oriented graphics».
Самой простой аналогией векторного изображения может служить аппликация. Все изображение состоит из отдельных кусочков различной формы и цвета (даже части растра), «склеенных» между собой. Понятно, что таким образом трудно получить фотореалистичное изображение, так как на нем сложно выделить конечное число примитивов, однако существенными достоинствами векторного способа представления изображения, по сравнению с растровым, являются:
· векторное изображение может быть легко масштабировано без потери качества, так как это требует пересчета сравнительно небольшого числа координат узлов;
· графические файлы, в которых хранятся векторные изображения, имеют существенно меньший, по сравнению с растровыми, объем (порядка нескольких килобайт).
Сферы применения векторной графики очень широки. В полиграфике – от создания красочных иллюстраций до работы со шрифтами. Все, что мы называем машинной графикой, 3D-графикой, графическими средствами компьютерного моделирования и САПР – все это сферы приоритета векторной графики, ибо эти ветви дерева компьютерных наук рассматривают изображение исключительно с позиции его математического представления.
Как видно, векторным можно назвать только способ описания изображения, а само изображение для нашего глаза всегда растровое. Таким образом, задачами векторного графического редактора являются растровая прорисовка графических примитивов и предоставление пользователю сервиса по изменению параметров этих примитивов. Все изображение представляет собой базу данных примитивов и параметров макета (размеры холста, единицы измерения и т. д.). Отрисовать изображение – значит выполнить последовательно процедуры прорисовки всех его деталей.
Для уяснения разницы между растровой и векторной графикой приведем простой пример. Вы решили отсканировать Вашу фотографию размером 10´15 см чтобы затем обработать и распечатать на цветном принтере. Для получения приемлемого качества печати необходимо разрешение не менее 300 dpi. Считаем:
10 см = 3,9 дюйма; 15 см = 5,9 дюймов.
По вертикали: 3,9 * 300 = 1170 точек.
По горизонтали: 5,9 * 300 = 1770 точек.
Итак, число пикселей растровой матрицы 1170 * 1770 = 2 070 900.
Теперь решим, сколько цветов мы хотим использовать. Для черно-белого изображения используют обычно 256 градаций серого цвета для каждого пикселя, или 1 байт. Получаем, что для хранения нашего изображения надо 2 070 900 байт или 1,97 Мб.
Для получения качественного цветного изображения надо не менее 256 оттенков для каждого базового цвета. В модели RGB соответственно их 3: красный, зеленый и синий. Получаем общее количество байт – 3 на каждый пиксел. Соответственно, размер хранимого изображения возрастает в три раза и составляет 5,92 Мб.
Для создания макета для полиграфии фотографии сканируют с разрешением 600 dpi, следовательно, размер файла вырастает еще вчетверо.
С другой стороны, если изображение состоит из простых объектов, то для его хранения в векторном виде необходимо не более нескольких килобайт.
ИНФОРМАЦИЯ, КАЧЕСТВО И КОЛИЧЕСТВО ИНФОРМАЦИИ
ЛЕКЦИЯ №1. ПОНЯТИЕ ИНФОРМАЦИИ. ОБЩАЯ ХАРАКТЕРИСТИКА ПРОЦЕССОВ СБОРА, ПЕРЕДАЧИ, ОБРАБОТКИ И НАКОПЛЕНИЯ ИНФОРМАЦИИ
План
o Информация, качество и количество информации.
o Информационные процессы.
o Основные задачи информатики.
ИНФОРМАЦИЯ, КАЧЕСТВО И КОЛИЧЕСТВО ИНФОРМАЦИИ
Термин информация используется во многих сферах человеческой деятельности. Он происходит от латинского слова informatio, что означает «сведения, разъяснения,
В широком смысле информация — это сведения и знания, являющиеся объектом хранения, преобразования, передачи и помогающие решить поставленную задачу.
Приведем некоторые основные понятия информации.
Информация, предназначенная передаче, называется сообщением. Сообщение может быть представлено в виде знаков и символов, преобразовано и закодировано в определенную последовательность электрических сигналов.
Информация, представленная в виде, пригодном для обработки людьми или компьютером, называется данными. Чаще всего имеют дело с тремя типами данных: числовыми, текстовыми и графическими.
Для того чтобы происходил обмен информацией, ее преобразование и передача, должны быть источник информации, передатчик, канал связи, приемник и получатель информации, образующие информационную систему. Обычно в качестве получателя выступает человек, который оценивает информацию с точки зрения ее применимости для решения поставленной задачи. Процедура оценки информации человеком проходит в три этапа, определяющие ее синтаксический, семантический и прагматический аспекты.
Вначале человек наблюдает некоторый факт действительности в виде определенного набора данных вне зависимости от их смысловых и потребительских качеств. Здесь проявляется синтаксический аспект.
Затем человек путем сопоставления полученных данных с тезаурусом — полным систематизированным набором данных и знаний в какой-либо области — формирует знание о наблюдаемом факте. Это семантический аспект информации.
На основании полученных знаний человек оценивает практическую полезность информации для достижения поставленных целей, что и отражает ее прагматический аспект.
Эффективность функционирования любых систем во многом определяется качеством используемой информации.
Качество информацииопределяется некоторыми ее свойствами, отвечающими потребностям (целям, задачам) пользователей.
Рассмотрим такие важные характеристики качества информации, как полноту, достоверность, доступность, актуальность.
Полнота информации характеризует степень достаточности данных для принятия решения или создания новых данных на основе имеющихся. Неполный набор данных оставляет большую долю неопределенности, т. е. большое число вариантов выбора, а это потребует применения дополнительных методов, например экспертных оценок, бросания жребия и т. п. Избыточный набор данных затрудняет доступ к нужным данным, создает повышенный информационный шум, что также вызывает необходимость применения дополнительных методов, например фильтрации, сортировки.
Достоверность информации — это свойство, характеризующее степень соответствия информации реальному объекту с необходимой точностью. При работе с неполным
набором данных достоверность информации может характеризоваться вероятностью: например, можно сказать, что при бросании монеты с вероятностью 50% выпадет герб.
Доступность информации — это возможность получения информации при необходимости. Доступность складывается из двух составляющих: из доступности данных и доступности методов. Отсутствие хотя бы одного дает неадекватную информацию.
Актуальность информации характеризует ее способность сохранять ценность для потребителя в течение времени, т. е. не устаревать. Информация существует во времени, так как существуют во времени все информационные процессы. Информация, актуальная сегодня, может стать совершенно ненужной по истечении некоторого времени.
Свойство полноты информации предполагает, что имеется возможность измерять количество информации.Для оценки и измерения количества информации в сообщении применяются различные подходы, среди которых следует выделить статистический, алфавитный и объемный.
Статистический подход получил развитие в работах Р. Хартли, К. Шеннона, А. Н. Колмогорова и др. В 1928 г. американский инженер Р. Хартли предложил оценивать количество информации в сообщении логарифмом числа N возможных равновероятных состояний.
Алфавитный подход позволяет определить количество текстовой информации.
Объемный подход предполагает количественную оценку информации в определенных единицах. За минимальную единицу информации принимается один бит (англ. bit — binary digit — двоичная цифра). Бит — слишком мелкая единица измерения информации. На практике чаще применяются более крупные единицы, например байт, являющийся последовательностью из восьми битов. Широко используются еще более крупные производные единицы информации:
• 1 килобайт (Кбайт) = 1024 байт == 2 10 байт;
• 1 мегабайт (Мбайт) = 1024 Кбайт = 2 20 байт;
• 1 гигабайт (Гбайт) = 1024 Мбайт = 2 30 байт;
• 1 терабайт (Тбайт) = 1024 Гбайт = 2 40 байт.
ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ
Получение и использование информации тесно связано с информационными процессами, поэтому имеет смысл рассмотреть отдельно их виды.
Сбор данных — это деятельность субъекта по накоплению данных с целью обеспечения достаточной полноты.
Соединяясь с адекватными методами, данные рождают информацию, способную помочь в принятии решения. Например, интересуясь ценой товара, его потребительскими свойствами, мы собираем информацию для того, чтобы принять решение: покупать или не покупать его.
Передача данных — это процесс обмена данными. Предполагается, что существует источник информации, канал связи, приемник информации и между ними приняты соглашения о порядке обмена данными, эти соглашения называются протоколами обмена. Скорость передачи информации измеряется в бодах (1 бод = 1 бит/с).
Хранение данных — это поддержание данных в форме, постоянно готовой к выдаче их потребителю. Одни и те же данные могут быть востребованы неоднократно, поэтому разрабатывается способ их хранения (обычно на материальных носителях) и методы доступа к ним по запросу потребителя.
Обработка данных — это процесс преобразования информации от исходной ее формы до определенного результата. Сбор, накопление, хранение информации часто не являются конечной целью информационного процесса. Чаще всего первичные данные привлекаются для решения какой-либо проблемы, затем они преобразуются шаг за шагом в соответствии с алгоритмом решения задачи до получения необходимых выходных данных.
| | | следующая лекция ==> | |
| Расчет глубины заложения фундамента | | | по лабораторной работе № 1 |
Дата добавления: 2016-12-31 ; просмотров: 1565 | Нарушение авторских прав
- http://informatika.neznaka.ru/answer/3368631_kakoe-kolicestvo-informacii-s-tocki-zrenia-alfavitnogo-podhoda-soderzit-slovo-informatika-esli-scitat-cto-alfavit-sostoit-iz-32-bukv/
- http://csaa.ru/izmerenie-informacii-mery-informacii-podhody-k/
- http://videouroki.net/video/06-kolichestvo-informacii.html
- http://ppt-online.org/2453
- http://studfiles.net/preview/2180025/page:4/
- http://lektsii.org/13-52697.html