1. Какими свойствами обладает память человека?

2. Чем отличается память человека от памяти человечества?

3. Почему информацию, которую мы помним наизусть, можно назвать оперативной? Приведите примеры оперативной информации, которой вы владеете.

4. Какие сведения вы храните в своей записной книжке? Как можно назвать записную книжку с точки зрения хранения информации?

5. Перечислите достоинства словами, что такое носитель информации в оперативной и долговременной памяти.

6. Объясните своими словами, что такое носитель информации. Какие носители информации вам известны? Каким носителем информации вы пользуетесь чаще всего?

8. В слудующих примерах укажите информационный носитель и форму представления информации:
а) табличка с номером дома
б) почтовая открытка
в) билет на поезд
д) диск со сборником мультфильмов

9. Что такое файл?

10. Какие правила именования файлов вам известны?


11. Сравните хранение файлов в компьютере и книг в библиотеке.
Понятие файла имеет особое значение в любой операционной системе, включая самую распространенную систему Windows. Каждый, кто начинает изучать компьютер с нуля, сталкивается с этим компьютерным терминов в числе самых первых изучаемых. Что же такое файл? Возьмем аналогию с человеком, который всю информацию разделяет на части для удобства ее хранения, поиска и использования. В качестве примера можно привести библиотеку, где каждая книга объединена общим смыслом содержания, имеет определенное количество страниц, свое место хранения и расставлена на полках по жанрам. Компьютер же оперирует разного рода информацией (тексты, фотографии, видео и т.д.) в виде нулей и единиц, понятному только ему. Человек в таком виде воспринимать информацию не может. Поэтому для полноценного взаимопонимания ввели понятие файла.
Файл и его основные свойства
Файл представляет собой подобие контейнера, в котором храниться какая-либо информация. Это может быть тот же текст, фотография, фильм, или же набор данных, нужных для работы определенной программе или самой операционной системе. Таким образом, из файлов состоят все программы и данные, имеющиеся на компьютере. Фильм, хранящийся на жестком диске или другом носителе – это файл, два фильма – это два файла. Фотография – это файл, две фотографии – это два файла и т.п. По аналогии с библиотекой, жесткий диск или другой носитель – это своего рода хранилище файлов, которые имеют свои места хранения, имена и размеры. Отсюда мы подходим к тому, что файлы имеют определенные свойства. Основные свойства – это имя файла, размер файла, расширение.
Чтобы отличить один файл от другого он имеет имя, которое может состоять из строчных или заглавных букв, цифр или всех вместе. Имя файла не следует начинать с точки, также в имени файла избегайте использовать квадратные и фигурные скобки, недопустимы спецсимволы / \ | : * ? “ . При ошибочном наименовании файлов с использованием этих знаков, операционная система откажется принять имя, указав при этом на ошибку. Имя файла не должно содержать более 255 символов, хотя вполне достаточно 10-30 символов.
Кто или что дает имена файлам? Имена дают программы и сама операционная система для своих служебных данных, которые нельзя переименовывать во избежание сбоев в их работе. Те файлы, которые вы сами создаете с помощью программ, вы именуете сами, придерживаясь вышеперечисленными ограничениями. Например, создав тестовый документ в любом текстовом редакторе вы можете назвать его «мой документ» или по другому.

Могут ли быть два или несколько одинаковых имен файла в одном месте на носителе, и если могут, то как понять, какая информация в них хранится? Да могут, но в случае разного их расширения.
Расширение файла
Расширение является частью имени файла и указывается после точки. Пример:
- Readme.txt
- Readme.avi
- Readme.jpeg
- Readme.mp3
Здесь одинаковые имена, но с разными расширениями и они могут находиться в одном месте. Расширение файла необходимо для того, чтобы компьютер знал, с помощью какой программы ему нужно обработать файл. Если дважды щелкнуть мышкой на файле с расширением txt, то Windows запустит программу «Блокнот» и автоматически загрузит в него текст, содержащийся в файле.
Кроме того, по расширению пользователь быстро поймет, что за информация хранится в файле. Для простоты понимания возьмите аналогию с человеком, представьте, что расширение — это фамилия. Т.е. имея список с одинаковыми именами людей, вы отличите их по фамилии. Самые распространенные расширения, с которыми вы будете работать – это:
- .txt — простой текстовый документ;
- .doc, .docx, .docm, .rtx — форматированный текстовый документ;
- .xls, .xlsx, .xlsm, .ods — электронные таблицы;
- .jpg, .jpeg, .gif, .png — графические;
- .mp3, .ogg, .wma — аудиофайлы;
- .mpeg, .264, .avi — видео;
- .rar, .zip, .tg — архивы;
- .exe, .cmd, .bat — исполняемые файлы.
Расширение еще называют типом файла. Регистр расширения не имеет значения: txt и TXT – это одно и то же расширение.
Размер файла
Каждый файл занимает место на жестком диске или любом другом носителе. Занимаемое место определяется размером файла, который измеряется в единицах информации — байтах, килобайтах, мегабайтах и гигабайтах, а в будущем возможно и в терабайтах. Можно привести аналогию с весом: грамм, килограмм, центнер, тонна. Кстати, часто на компьютерном жаргоне можно услышать «фильм (игра) весит 2 гига». Это значит, что файл с фильмом имеет размер 2 гигабайта. Для компьютера самый маленький размер исчисляется в 1 бит, но в нем практически не измеряют, настолько он мал. Исчисление начинают с байта, который содержит 8 бит и далее:
- 1 Килобайт (Кб) = 1024 байта
- 1 Мегабайт (Мб) = 1024 кб (килобайта)
- 1 Гигабайт (Гб) = 1024 мб (мегабайта)
- 1 Терабайт (Тб) = 1024 Гб (гигабайта)
Кратность 1024 образуется из основных принципов двоичного счисления. Что бы узнать размер файла в стандартном окне проводника Windows, нужно навести курсор мыши на значок нашего файла, нажать правой кнопкой мышки и из выпавшего списка выбрать пункт «Свойства». Открывшееся окно покажет не только размер, но и другие свойства документа.

Кроме имени, расширения и размера, файл имеет еще ряд свойств, которые представляют интерес для продвинутых пользователей. Для компьютерных чайников, изучающих компьютер с нуля, в первое время будет достаточно вышеперечисленных.
Файлы с точки зрения пользователя
История систем управления данными во внешней памяти начинается еще с магнитных лент, но современный облик они приобрели с появлением магнитных дисков. До этого каждая прикладная программа сама решала проблемы именования данных и их структуризации во внешней памяти . Это затрудняло поддержание на внешнем носителе нескольких архивов долговременно хранящейся информации. Историческим шагом стал переход к использованию централизованных систем управления файлами . Система управления файлами берет на себя распределение внешней памяти , отображение имен файлов в адреса внешней памяти и обеспечение доступа к данным.
Файловая система — это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти , и обеспечить пользователю удобный интерфейс при работе с такими данными. Организовать хранение информации на магнитном диске непросто. Это требует, например, хорошего знания устройства контроллера диска, особенностей работы с его регистрами. Непосредственное взаимодействие с диском — прерогатива компонента системы ввода-вывода ОС, называемого драйвером диска. Для того чтобы избавить пользователя компьютера от сложностей взаимодействия с аппаратурой, была придумана ясная абстрактная модель файловой системы. Операции записи или чтения файла концептуально проще, чем низкоуровневые операции работы с устройствами.
Основная идея использования внешней памяти состоит в следующем. ОС делит память на блоки фиксированного размера, например, 4096 байт. Файл , обычно представляющий собой неструктурированную последовательность однобайтовых записей, хранится в виде последовательности блоков (не обязательно смежных); каждый блок хранит целое число записей. В некоторых ОС (MS-DOS) адреса блоков, содержащих данные файла , могут быть организованы в связный список и вынесены в отдельную таблицу в памяти. В других ОС (Unix) адреса блоков данных файла хранятся в отдельном блоке внешней памяти (так называемом индексе или индексном узле). Этот прием, называемый индексацией , является наиболее распространенным для приложений, требующих произвольного доступа к записям файлов . Индекс файла состоит из списка элементов, каждый из которых содержит номер блока в файле и сведения о местоположении данного блока. Считывание очередного байта осуществляется с так называемой текущей позиции, которая характеризуется смещением от начала файла . Зная размер блока, легко вычислить номер блока, содержащего текущую позицию. Адрес же нужного блока диска можно затем извлечь из индекса файла . Базовой операцией, выполняемой по отношению к файлу , является чтение блока с диска и перенос его в буфер , находящийся в основной памяти.
Файловая система позволяет при помощи системы справочников ( каталогов , директорий ) связать уникальное имя файла с блоками вторичной памяти, содержащими данные файла . Иерархическая структура каталогов , используемая для управления файлами , может служить другим примером индексной структуры. В этом случае каталоги или папки играют роль индексов, каждый из которых содержит ссылки на свои подкаталоги. С этой точки зрения вся файловая система компьютера представляет собой большой индексированный файл . Помимо собственно файлов и структур данных, используемых для управления файлами ( каталоги , дескрипторы файлов , различные таблицы распределения внешней памяти ), понятие » файловая система » включает программные средства , реализующие различные операции над файлами .
Перечислим основные функции файловой системы.
- Идентификация файлов . Связывание имени файла с выделенным ему пространством внешней памяти .
- Распределение внешней памяти между файлами . Для работы с конкретным файлом пользователю не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того чтобы загрузить документ в редактор с жесткого диска, нам не нужно знать, на какой стороне какого магнитного диска, на каком цилиндре и в каком секторе находится данный документ.
- Обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера.
- Обеспечение защиты от несанкционированного доступа.
- Обеспечение совместного доступа к файлам , так чтобы пользователю не приходилось прилагать специальных усилий по обеспечению синхронизации доступа.
- Обеспечение высокой производительности.
Иногда говорят, что файл — это поименованный набор связанной информации, записанной во вторичную память. Для большинства пользователей файловая система — наиболее видимая часть ОС. Она предоставляет механизм для онлайнового хранения и доступа как к данным, так и к программам для всех пользователей системы. С точки зрения пользователя, файл — единица внешней памяти , то есть данные, записанные на диск, должны быть в составе какого-нибудь файла .
Важный аспект организации файловой системы — учет стоимости операций взаимодействия с вторичной памятью. Процесс считывания блока диска состоит из позиционирования считывающей головки над дорожкой, содержащей требуемый блок, ожидания, пока требуемый блок сделает оборот и окажется под головкой, и собственно считывания блока. Для этого требуется значительное время (десятки миллисекунд). В современных компьютерах обращение к диску осуществляется примерно в 100 000 раз медленнее, чем обращение к оперативной памяти. Таким образом, критерием вычислительной сложности алгоритмов, работающих с внешней памятью , является количество обращений к диску.
В данной лекции рассматриваются вопросы структуры, именования, защиты файлов ; операции , которые разрешается производить над файлами ; организация файлового архива (полного дерева справочников). Проблемы выделения дискового пространства, обеспечения производительной работы файловой системы и ряд других вопросов, интересующих разработчиков системы, вы найдете в следующей лекции.
Общие сведения о файлах
Имена файлов
Файлы представляют собой абстрактные объекты. Их задача — хранить информацию, скрывая от пользователя детали работы с устройствами. Когда процесс создает файл , он дает ему имя. После завершения процесса файл продолжает существовать и через свое имя может быть доступен другим процессам.
Правила именования файлов зависят от ОС. Многие ОС поддерживают имена из двух частей (имя+расширение), например progr.c ( файл , содержащий текст программы на языке Си) или autoexec.bat ( файл , содержащий команды интерпретатора командного языка). Тип расширения файла позволяет ОС организовать работу с ним различных прикладных программ в соответствии с заранее оговоренными соглашениями. Обычно ОС накладывают некоторые ограничения, как на используемые в имени символы, так и на длину имени файла . В соответствии со стандартом POSIX, популярные ОС оперируют удобными для пользователя длинными именами (до 255 символов).
Типы файлов
Важный аспект организации файловой системы и ОС — следует ли поддерживать и распознавать типы файлов . Если да, то это может помочь правильному функционированию ОС, например не допустить вывода на принтер бинарного файла .
Основные типы файлов : регулярные (обычные) файлы и директории (справочники, каталоги ). Обычные файлы содержат пользовательскую информацию. Директории — системные файлы , поддерживающие структуру файловой системы. В каталоге содержится перечень входящих в него файлов и устанавливается соответствие между файлами и их характеристиками ( атрибутами ). Мы будем рассматривать директории ниже.
Напомним, что хотя внутри подсистемы управления файлами обычный файл представляется в виде набора блоков внешней памяти , для пользователей обеспечивается представление файла в виде линейной последовательности байтов. Такое представление позволяет использовать абстракцию файла при работе с внешними устройствами, при организации межпроцессных взаимодействий и т. д. Так, например, клавиатура обычно рассматривается как текстовый файл , из которого компьютер получает данные в символьном формате. Поэтому иногда к файлам приписывают другие объекты ОС, например специальные символьные файлы и специальные блочные файлы , именованные каналы и сокеты, имеющие файловый интерфейс. Эти объекты рассматриваются в других разделах данного курса.
Далее речь пойдет главным образом об обычных файлах.
Обычные (или регулярные) файлы реально представляют собой набор блоков (возможно, пустой) на устройстве внешней памяти , на котором поддерживается файловая система. Такие файлы могут содержать как текстовую информацию (обычно в формате ASCII), так и произвольную двоичную (бинарную) информацию.
Текстовые файлы содержат символьные строки, которые можно распечатать, увидеть на экране или редактировать обычным текстовым редактором.
Другой тип файлов — нетекстовые, или бинарные, файлы . Обычно они имеют некоторую внутреннюю структуру. Например, исполняемый файл в ОС Unix имеет пять секций: заголовок, текст, данные, биты реаллокации и символьную таблицу. ОС выполняет файл , только если он имеет нужный формат. Другим примером бинарного файла может быть архивный файл . Типизация файлов не слишком строгая.
Обычно прикладные программы, работающие с файлами , распознают тип файла по его имени в соответствии с общепринятыми соглашениями. Например, файлы с расширениями .c , .pas , .txt — ASCII-файлы, файлы с расширениями .exe — выполнимые, файлы с расширениями .obj , .zip — бинарные и т. д.
Атрибуты файлов
Кроме имени ОС часто связывают с каждым файлом и другую информацию, например дату модификации, размер и т. д. Эти другие характеристики файлов называются атрибутами . Список атрибутов в разных ОС может варьироваться. Обычно он содержит следующие элементы: основную информацию (имя, тип файла ), адресную информацию (устройство, начальный адрес, размер), информацию об управлении доступом (владелец, допустимые операции) и информацию об использовании (даты создания, последнего чтения, модификации и др.).
Список атрибутов обычно хранится в структуре директорий (см. следующую лекцию) или других структурах, обеспечивающих доступ к данным файла .
Организация файлов и доступ к ним
Программист воспринимает файл в виде набора однородных записей. Запись — это наименьший элемент данных , который может быть обработан как единое целое прикладной программой при обмене с внешним устройством. Причем в большинстве ОС размер записи равен одному байту. В то время как приложения оперируют записями, физический обмен с устройством осуществляется большими единицами (обычно блоками). Поэтому записи объединяются в блоки для вывода и разблокируются — для ввода. Вопросы распределения блоков внешней памяти между файлами рассматриваются в следующей лекции.
ОС поддерживают несколько вариантов структуризации файлов .
Последовательный файл
Простейший вариант — так называемый последовательный файл . То есть файл является последовательностью записей. Поскольку записи, как правило, однобайтовые, файл представляет собой неструктурированную последовательность байтов.
Обработка подобных файлов предполагает последовательное чтение записей от начала файла , причем конкретная запись определяется ее положением в файле . Такой способ доступа называется последовательным (модель ленты). Если в качестве носителя файла используется магнитная лента, то так и делается. Текущая позиция считывания может быть возвращена к началу файла ( rewind ).
Файл прямого доступа
В реальной практике файлы хранятся на устройствах прямого (random) доступа, например на дисках, поэтому содержимое файла может быть разбросано по разным блокам диска, которые можно считывать в произвольном порядке. Причем номер блока однозначно определяется позицией внутри файла .
Здесь имеется в виду относительный номер, специфицирующий данный блок среди блоков диска, принадлежащих файлу . О связи относительного номера блока с абсолютным его номером на диске рассказывается в следующей лекции.
Естественно, что в этом случае для доступа к середине файла просмотр всего файла с самого начала не обязателен. Для специфицирования места, с которого надо начинать чтение, используются два способа: с начала или с текущей позиции, которую дает операция seek. Файл , байты которого могут быть считаны в произвольном порядке, называется файлом прямого доступа .
Таким образом, файл , состоящий из однобайтовых записей на устройстве прямого доступа, — наиболее распространенный способ организации файла . Базовыми операциями для такого рода файлов являются считывание или запись символа в текущую позицию. В большинстве языков высокого уровня предусмотрены операторы посимвольной пересылки данных в файл или из него.
Подобную логическую структуру имеют файлы во многих файловых системах, например в файловых системах ОС Unix и MS-DOS. ОС не осуществляет никакой интерпретации содержимого файла . Эта схема обеспечивает максимальную гибкость и универсальность. С помощью базовых системных вызовов (или функций библиотеки ввода/вывода) пользователи могут как угодно структурировать файлы . В частности, многие СУБД хранят свои базы данных в обычных файлах .
Другие формы организации файлов
Известны как другие формы организации файла , так и другие способы доступа к ним, которые использовались в ранних ОС, а также применяются сегодня в больших мэйнфреймах (mainframe), ориентированных на коммерческую обработку данных.
Первый шаг в структурировании — хранение файла в виде последовательности записей фиксированной длины, каждая из которых имеет внутреннюю структуру. Операция чтения производится над записью, а операция записи переписывает или добавляет запись целиком. Ранее использовались записи по 80 байт (это соответствовало числу позиций в перфокарте) или по 132 символа (ширина принтера). В ОС CP/M файлы были последовательностями 128-символьных записей. С введением CRT-терминалов данная идея утратила популярность.
Другой способ представления файлов — последовательность записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи (см. рис. 11.1). Базисная операция в данном случае — считать запись с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, отсортированные по значению ключевого поля) или в более сложном порядке. Метод доступа по значению ключевого поля к записям последовательного файла называется индексно-последовательным.
В некоторых системах ускорение доступа к файлу обеспечивается конструированием индекса файла . Индекс обычно хранится на том же устройстве, что и сам файл , и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись. Такие файлы называются индексированными, а метод доступа к ним — доступ с использованием индекса.
Предположим, у нас имеется большой несортированный файл , содержащий разнообразные сведения о студентах, состоящие из записей с несколькими полями, и возникает задача организации быстрого поиска по одному из полей, например по фамилии студента. Рис. 11.2 иллюстрирует решение данной проблемы — организацию метода доступа к файлу с использованием индекса.
Следует отметить, что почти всегда главным фактором увеличения скорости доступа является избыточность данных.
Способ выделения дискового пространства при помощи индексных узлов, применяемый в ряде ОС (Unix и некоторых других, см. следующую лекцию), может служить другим примером организации индекса.
В этом случае ОС использует древовидную организацию блоков, при которой блоки, составляющие файл , являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоков файла . Для больших файлов индекс может быть слишком велик. В этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
13. Файлы с точки зрения пользователя.
История систем управления данными во внешней памяти начинается еще с магнитных лент, но современный облик они приобрели с появлением магнитных дисков. До этого каждая прикладная программа сама решала проблемы именования данных и структуризации данных во внешней памяти. Это затрудняло поддержание на внешнем носителе нескольких архивов долговременно хранимой информации. Историческим шагом явился переход к использованию централизованных систем управления файлами. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в адреса внешней памяти и обеспечение доступа к данным.
Файловая система — это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти и обеспечить пользователю удобный интерфейс при работе с этими данными. Организовать хранение информации на магнитном диске непросто. Это требует хорошего знания устройства контроллера диска, особенностей работы с его регистрами и.т. д. (этим обычно занимается компонент системы ввода-вывода ОС, называемый драйвером диска). Для того чтобы избавить пользователя компьютера от сложностей взаимодействия с аппаратурой и была придумана ясная абстрактная модель файловой системы. Операции записи или чтения файла концептуально проще, чем низкоуровневые операции работы с устройствами. Основная идея использования внешней памяти состоит в следующем. ОС делит ее на блоки фиксированного размера, например, 4096 байт. С точки зрения пользователя каждый файл состоит из набора индивидуальных элементов, называемых записями (например, характеристика какого-нибудь объекта). Каждый файл хранится в виде определенной последовательности блоков (не обязательно смежных); каждый блок хранит целое число записей. В некоторых ОС (MS-DOS) адреса блоков, содержащих данные файла, могут быть организованы в связный список и вынесены в отдельную таблицу в памяти. В других ОС (Unix), адреса блоков данных файла хранятся в отдельном блоке внешней памяти (так называемом индексе или индексном узле). Этот прием называется индексацией и является наиболее распространенным для приложений, требующих произвольного доступа к записям файлов. Индекс файла состоит из списка элементов, каждый из которых содержит номер блока в файле и указание о местоположении данного блока. В современных ОС файлы обычно представляют собой неструктурированную последовательность байтов (длина записи равна 1) и считывание очередного байта осуществляется с так называемой текущей позиции, которая характеризуется смещением от начала файла. Зная размер блока, легко вычислить номер блока, содержащего текущую позицию. Адрес же нужного блока диска можно затем извлечь из индекса файла. Базовой операцией, выполняемой по отношению к файлу, является чтение блока с диска и перенос его в буфер, находящийся в основной памяти.
Файловая система позволяет при помощи системы справочников (каталогов, директорий) связать уникальное имя файла с блоками вторичной памяти, содержащими данные файла. Иерархическая структура каталогов, используемая для управления файлами, является другим примером индексной структуры. В этом случае каталоги или папки играют роль индексов, каждый из которых содержит ссылки на свои подкаталоги. С этой точки зрения вся файловая система компьютера представляет собой большой индексированный файл.
Понятие «файловая система» включает [30]:
совокупность всех файлов на диске,
наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске,
комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами.
Файлы управляются ОС. То, как они структурированы, поименованы, используются, защищены, реализованы – одна из главных тем проектирования ОС. Перечислим основные функции файловой системы:
Идентификация файлов. Связывание имени файла с выделенным ему пространством внешней памяти.
Распределение внешней памяти между файлами. Для работы с конкретным файлом не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того, чтобы загрузить документ в редактор с жесткого диска нам не требуется знать на какой стороне какого магнитного диска и на каком цилиндре и в каком секторе находится требуемый документ.
Обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера.
Обеспечение защиты от НСД.
Обеспечение совместного доступа к файлам, не требуя от пользователя специальных усилий по обеспечению синхронизации доступа.
Обеспечение высокой производительности.
Иногда говорят, что файл — поименованный набор связанной информации, записанной во вторичную память. Для большинства пользователей файловая система — наиболее видимая часть ОС. Она предоставляет механизм для он-лайнового хранения и доступа, как данным, так и программам ОС для всех пользователям системы. С точки зрения пользователя файл — минимальная величина внешней памяти, то есть данные, записанные на диск должны быть в составе какого-нибудь файла.
Важный аспект организации файловой системы – учет стоимости операций взаимодействия с вторичной памятью. Процесс считывания блока диска состоит из позиционирования считывающей головки над дорожкой, содержащей требуемый блок, ожидания, пока требуемый блок сделает оборот и окажется под головкой и собственно считывания блока. Для этого требуется значительное время (десятки миллисекунд). В современных компьютерах обращение к диску примерно в 100000 медленнее, чем обращение к памяти. Таким образом, критерием вычислительной сложности алгоритмов, работающих с внешней памятью, является количество обращений к диску. Имена файлов
Файлы – абстрактные объекты. Они предоставляют пользователям возможность сохранять информацию, скрывая от него детали того, как и где она хранится и то, как диски в действительности работают. Вероятно, одна из наиболее важных характеристик любого абстрактного механизма – способ именования объектов, которыми он управляет. Когда процесс создает файл, он дает файлу имя. После завершения процесса файл продолжает существовать и через свое имя может быть доступен другим процессам. Многие ОС поддерживают имена из двух частей (имя+расширение), например progr.c(файл, содержащий текст программы на языке Си) или autoexec.bat (файл, содержащий команды интерпретатора командного языка). Тип расширения файла позволяет ОС организовать работу с ним различных прикладных программ в соответствии с заранее оговоренными соглашениями.
Обычно ОС накладывают некоторые ограничения, как на используемые в имени символы, так и на длину имени. Например, в ОС Unix учитывается регистр при вводе имени файла (case sensitive), а в MS-DOS – нет. В популярной файловой системе FAT длина имен ограничивается известной схемой 8.3 (8 символов — собственно имя, 3 символа — расширение имени). Современные файловые системы, как правило, поддерживают более удобные для пользователя длинные символьные имена файлов. Так, в соответствии со стандартом POSIX, в ОС UNIX допускаются имена длиной до 255 символов, та же самая длина устанавливается для имен файлов и в ОС Windows NT для файловой системы NTFS.
Как уже говорилось, программист воспринимает файл в виде набора логических записей. Логическая запись — это наименьший элемент данных, которым может оперировать программа при обмене с внешним устройством. Даже если физический обмен с устройством осуществляется большими единицами (обычно блоками), операционная система обеспечивает программисту доступ к отдельной логической записи.
ОС поддерживают несколько вариантов структуризации файлов. Первый из них, файл, как неструктурированная последовательность байтов. Например, в файловых системах ОС UNIX и MS-DOS файл имеет простейшую логическую структуру – последовательность однобайтовых записей.
ОС не осуществляет никакой интерпретации этих байтов. Тем не менее, ОС с файловыми системами данного типа должны поддерживать, по крайней мере, одну структуру — выполняемый файл — для запуска программ. Этой схеме присущи максимальная гибкость и универсальность. Используя базовые системные вызовы (или функции библиотеки ввода/вывода), пользователи могут, как угодно структурировать файлы. В частности, многие СУБД хранят свои базы данных в обычных файлах.
Первый шаг в структурировании — хранение файла в виде последовательности записей фиксированной длины, каждая из которых имеет внутреннюю структуру. Центральная идея этой схемы — операция чтения проводится над записью и операция записи — переписывает или добавляет запись целиком. Ранее были записи по 80 байт (соответствовало числу позиций в перфокарте) или по 132 символа (ширина принтера). В ОС CP/M файлы были последовательностями 128-символьных записей. С введением CRT терминалов эта идея утратила популярность.
Третий способ представления файлов — последовательность записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи. Базисная операция в данном случае — считать запись с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, будучи отсортированы по значению ключевого поля) или в более сложном порядке.

Рис. 11.. Файл, как последовательность записей переменной длины
Использование индексов файлов, хранящих адреса записей, позволяет обеспечить быстрый доступ к отдельной записи (индексно-последовательная организация, см. также раздел 11.5). При добавлении новой записи в файл, место, куда ее поместить будет определено не пользователем, а операционной системой. Такой способ применяется в больших мэйнфреймах для коммерческих процессов обработки данных.
Типы и атрибуты файлов
Важный аспект дизайна файловой системы и ОС — следует ли поддерживать и распознавать типы файлов. Если да, то это может помочь правильному функционированию ОС, например не допустить вывода на принтер бинарного файла. К типам файлов, поддерживаемых современными ОС, относят регулярные (обычные) файлы и директории. Обычные (регулярные) файлы содержат пользовательскую информацию. Директории (справочники, каталоги) — системные файлы, поддерживающие структуру файловой системы. В каталоге содержится перечень файлов, входящих в него, и устанавливается соответствие между файлами и их характеристиками (атрибутами). Мы будем рассматривать директории ниже.
Напомним, что хотя внутри подсистемы управления файлами обычный файл представляется в виде набора блоков внешней памяти, для пользователей обеспечивается представление файла в виде линейной последовательности байтов. Такое представление позволяет использовать абстракцию файла при работе с внешними устройствами, при организации межпроцессных взаимодействий и т.д. Поэтому, иногда к файлам приписывают другие объекты ОС, например, специальные символьные файлы и специальные блочные файлы, именованные каналы и сокеты, имеющие файловый интерфейс. Эти объекты рассмотрены в других разделах данного курса.
Далее, главным образом, речь пойдет об обычных файлах.
Обычные (или регулярные) файлы реально представляют собой набор блоков (возможно, пустой) на устройстве внешней памяти, на котором поддерживается файловая система. Такие файлы могут содержать как текстовую информацию (обычно в формате ASCII), так и произвольную двоичную информацию.
Обычные регулярные файлы бывают — ASCII и бинарные.
ASCII файлы содержат строки текста, которые можно распечатать, увидеть на экране или редактировать обычным текстовым редактором.
Другой тип файлов – бинарные файлы, означает, что это не ASCII файлы. Обычно они имеют некоторую внутреннюю структуру. Например, выполнимый Unix файл имеет пять секций: заголовок, текст, данные, биты реаллокации и символьную таблицу. ОС выполняет файл, только если он имеет нужный формат. Другим примером бинарного файла может быть архивный файл.
Типизация файлов не слишком строгая.
Обычно прикладные программы, работающие с файлами, распознают тип файла по его имени в соответствии с общепринятыми соглашениями. Например, файлы с расширениями .c, .pas, .txt – ASCII файлы, файлы с расширениями .exe – выполнимые, файлы с расширениями .obj, .zip – бинарные и т.д.
Помимо имени ОС часто связывают с каждым файлом и другую информацию, например дату модификации, размер и т.д. Эти другие характеристики файлов называются атрибутами. Список атрибутов может варьироваться от одной ОС к другой. Он может включать: атрибуты защиты, пароль, имя создателя, флаги скрытости, архивности, системности, бинарности, тип доступа, длину записи, позицию ключа, время, дату, размер и т.д.
Эта информация обычно хранится в структуре директорий (см. раздел реализация директорий) или других структурах, обеспечивающих доступ к данным файла.
Доступ к файлам
Для использования информации, хранимой в файлах, она должна быть считана в память компьютера. Есть несколько способов доступа к файлам.
Ранние ОС давали только один способ доступа – последовательный (модель ленты). Записи считывались в порядке поступления. Текущая позиция считывания могла быть возвращена к началу файла (rewind). Вместе с магнитными барабанами и дисками появились файлы с прямым (random) доступом. Для специфицирования места, с которого надо начинать чтение используются два способа: с начала, или с текущей позиции, которую дает операция seek.
Последовательный доступ базируется на модели ленты и работает как на устройствах последовательного доступа, так и прямого. Это наиболее общая модель. Организация прямого доступа существенна для многих приложений, например, для систем управления базами данных.
Не все системы поддерживают оба (последовательный и прямой) метода доступа. Последовательный доступ легко эмулировать при помощи прямого, однако реализация прямого доступа через последовательный была бы очень неэффективной.
Помимо прямого и последовательного существуют и другие методы доступа. Обычно они включают конструирование индекса файла и базируются на прямом методе доступа. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись.
Способ выделения дискового пространства при помощи индексных узлов, применяемый в ряде ОС (Unix и ряде других, см. следующую главу) может служить другим примером организации индекса.
В этом случае ОС использует древовидную организацию блоков, при которой блоки, составляющие файл, являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоков файла. Для больших файлов индекс может быть слишком большим. В этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
Операции над файлами.
Операционная система должна предоставить в распоряжение пользователя набор операций для работы с файлами, реализованных через системные вызовы. Чаще всего при работе с файлом пользователь выполняет не одну, а несколько операций. Во-первых, нужно найти данные файла и его атрибуты по его символьному имени, во-вторых, считать необходимые атрибуты файла в отведенную область оперативной памяти и проанализировать права пользователя на выполнение требуемой операции. Затем выполнить операцию, после чего освободить занимаемую данными файла область памяти. Рассмотрим в качестве примера основные файловые операции ОС Unix:
Create. Создание файла, не содержащего данных. Смысл данного вызова — объявить, что файл существует и присвоить ему ряд атрибутов.
Delete. Удаление файла и освобождение занятого им дискового пространства.
Open. Перед использованием файла процесс должен его открыть. Цель данного системного вызова разрешить системе проанализировать атрибуты файла и проверить права доступа к файлу, а также считать в оперативную память список адресов блоков файла для быстрого доступа к его данным.
Close. Если работа с файлом завершена, его атрибуты и адреса блоков на диске больше не нужны. В этом случае файл нужно закрыть, чтобы освободить место во внутренних таблицах файловой системы.
Seek. Дает возможность специфицировать место внутри файла, откуда будет производиться считывание (или запись) данных, то есть задать текущую позицию.
Read. Чтение данных из файла. Обычно это происходит с текущей позиции. Пользователь должен задать объем считываемых данных и предоставить буфер для них.
Write. Запись данных в файл с текущей позиции. Если текущая позиция находится в конце файла, его размер увеличивается, в противном случае запись осуществляется на место имеющихся данных, которые, таким образом, теряются.
Get attributes. Предоставляет процессам нужные им сведения об атрибутах файла. В качестве примера можно привести, утилиту make, которая использует информацию о времени последней модификации файлов.
Set attributes. Дает возможность пользователю установить некоторые атрибуты. Наиболее очевидный пример — установка режима доступа к файлу.
Rename. Возможность переименования файла создает дополнительные удобства для пользователя. Данная операция может быть смоделирована копированием данного файла в файл с новым именем и последующим его удалением.
Директории. Логическая структура файлового архива.
Количество файлов на компьютере может быть большим. Отдельные системы хранят тысячи файлов, занимающие сотни гигабайтом диска. http://cs.mipt.ru/docs/courses/osstud/11/prep/sem11-12.htm — s1105Эффективное управление этими данными подразумевает наличие в них четкой логической структуры. Все современные файловые системы поддерживают многоуровневое именование файлов за счет поддержания во внешней памяти дополнительных файлов со специальной структурой – каталогов (или директорий).
Каждый каталог содержит список каталогов и/или файлов, содержащихся в данном каталоге. Каталоги имеют один и тот же внутренний формат, где каждому файлу соответствует одна запись в файле директории.

Рис. 11.3 Директории. (а) Атрибуты внутри записи в директории. (б) Атрибуты в другой структуре
Когда система открывает файл, она ищет имя файла в директории. Затем извлекаются атрибуты и адреса блоков файла на диске или непосредственно из записи в директории или из структуры, на которую запись в директории указывает. Эта информация помещается в системную таблицу в главной памяти. Все последующие ссылки на этот файл используют эту информацию.
Число директорий зависит от системы. В ранних ОС имелась только одна корневая директория, затем появились директории для пользователей (по одной директории на пользователя). В современных ОС используется произвольная структура дерева директорий.
Таким образом, файлы на диске образуют иерархическую древовидную структуру (см. рис. 11.4).
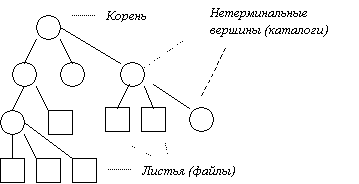 Рис. 11.4 Древовидная структура файловой системы.
Рис. 11.4 Древовидная структура файловой системы.
Существует несколько эквивалентных способов изображения дерева, структура перевернутого дерева, приведенного на рис.11.4, наиболее популярна. Верхнюю вершину называют корнем. Если элемент дерева не может иметь потомков, он называется терминальной вершиной или листом (в данном случае является файлом). Не листовые вершины – справочники или каталоги, содержат списки листовых и не листовых вершин. Путь от корня к файлу однозначно определяет файл.
Внутри одного каталога имена листовых файлов уникальны. Имена файлов, находящихся в разных каталогах могут совпадать. Для того чтобы однозначно определить файл по его имени (избежать коллизии имен) принято именовать файл полным именем (pathname), которое состоит из списка имен вложенных каталогов, по которому можно найти путь от корня к файлу, плюс имя файла в каталоге, непосредственно содержащем данный файл. Таким образом, имя включает цепочку имен — путь к файлу, например /usr/ast/mailbox . Это так называемое абсолютное имя. Такие имена уникальны. Компоненты пути разделяют символами ‘/’ (слеш) в Unix или обратными слешами в MS-DOS (в Multics – ‘>’).
Другой способ задания имени — относительный путь к файлу. Он использует концепцию рабочей или текущей директории, которая входит в состав окружения (environment) процесса, работающего с данным файлом. Например, в ОС Linux рабочая директория является частью структуры данных процесса. Тогда к файлам в такой директории можно ссылаться только по имени, при этом поиск файла будет осуществляться в рабочей директории. Это удобнее, но по существу то же самое, что и абсолютная форма.
Для получения доступа к файлу и локализации его блоков система должна выполнить навигацию по каталогам. Рассмотрим для примера путь /usr/linux/progr.c. Алгоритм одинаков для всех иерархических систем. Сначала в фиксированном месте на диске находится корневая директория. Затем находится компонент пути usr, т.е. в корневой директории ищется файл /usr. Исследуя этот файл, система понимает, что данный файл является каталогом, и блоки данных данного файла рассматривает как список файлов и ищет следующий компонент linux в нем. Из строки для linux находится файл, соответствующий компоненту usr/linux/. Затем также находится компонент progr.c, который затем открывается, заносится в таблицу открытых файлов и сохраняется в ней до закрытия файла.
Многие прикладные программы работают с файлами, находящимися в текущей директории, не указывая явным образом ее имени. Это дает возможность пользователю возможность произвольным образом именовать каталоги, содержащие различные программные пакеты. Для реализации этой возможности в большинстве ОС, поддерживающих иерархическую структуру директорий, используется обозначение ‘.’ — для текущей директории и ‘..’ — для родительской.
Операции над директориями
Так же, как и в случае файлов, система обязана обеспечить пользователя набором операций, необходимых для работы с директориями, реализованных через системные вызовы. Несмотря на то, что директории, это файлы, логика работы с ними отличается от логики работы с обычными файлами и определяется природой этих объектов, предназначенных поддерживать структуру файлового архива. Совокупность системных вызовов для управления директориями зависит от особенностей конкретной ОС. Рассмотрим в качестве примера некоторые системные вызовы ОС Unix.
Create. Создание директории. Вновь созданная директория включает записи с именами ‘.’ и ‘..’, однако считается пустой.
Delete. Удаление директории. Удалена может быть только пустая директория.
Opendir. Открытие директории для последующего чтения. Например, чтобы перечислить файлы, входящие в директорию, процесс должен открыть директорию и считать имена всех файлов, которые она включает.
Closedir. Закрытие директории после ее чтения для освобождения места во внутренних системных таблицах.
Readdir. Данный системный вызов возвращает содержимое текущей записи в открытой директории. Вообще говоря, для этих целей может быть использован системный вызов Read, но в этом случае от программиста потребуется знание внутренней структуры директории. Readdir возвращает содержимое записи в стандартном формате, независимо от используемой структуры директорий.
Rename. Имена директорий можно менять, также как и имена файлов.
Link. Связывание — это техника, которая позволяет информации о файле появляться более чем в одной директории. Данный системный вызов связывает существующий файл с абсолютным именем директории, используя их в качестве параметров. При помощи вызова Link можно связать файл сразу с несколькими директориями.
Unlink. Удаление записи о файле из директории. Если удаляемый файл присутствует только в одной директории, то он вообще удаляется из файловой системы, в противном случае система ограничивается только удалением специфицируемой записи.
Имеется также ряд других системных вызовов, например, связанных с защитой информации.
Информация в компьютерной системе должна быть защищена как от физического разрушения (reliability), так и от несанкционированного доступа (protection).
Здесь мы коснемся отдельных аспектов защиты, связанных с контролем доступа к файлам.
Контроль доступа к файлам
Наличие в системе многих пользователей предполагает организацию контролируемого доступа к файлам. Выполнение любой операции над файлом должно быть разрешено только в случае наличия у пользователя соответствующих привилегий. Обычно контролируются следующие операции: Read, Write, Execute, Append, Delete, List
Другие операции, например, копирование файлов или их переименование также могут контролироваться. Однако они чаще реализуются через перечисленные. Так, операцию копирования файлов можно представить как операцию чтения и последующую операцию записи.
Списки прав доступа
Наиболее общий подход к защите файлов от несанкционированного использования — сделать доступ зависящим от идентификатора пользователя, то есть связать с каждым файлом или директорией список прав доступа (access control list), где перечислены имена пользователей и типы разрешенных для них способов доступа к файлу. Любой запрос на выполнение операции сверяется с таким списком. Основная проблема реализации такого способа — список может быть длинным. Чтобы разрешить всем пользователям читать файл, необходимо всех их внести в список. У этой техники есть два нежелательных следствия:
Конструирование такого списка может быть сложной задачей, особенно если мы не знаем заранее список пользователей системы.
Запись в директории должна теперь иметь переменный размер (включать список потенциальных пользователей).
Для решения этих проблем создают классификации пользователей, например, в ОС Unix все пользователи разделены на три группы:
Группа (Group). Набор пользователей, разделяющих файл и нуждающихся в типовом способе доступа к нему.
что позволяет реализовать конденсированную версию списка прав доступа. В рамках этой ограниченной классификации задаются только три поля (по одному для каждой группы) для каждой контролируемой операции. В итоге, в Unix операции чтения, записи и исполнения контролируются при помощи 9 бит (rwxrwxrwx).
- http://www.pc-school.ru/chto-takoe-fajl-svojstva-fajla/
- http://www.intuit.ru/studies/courses/913/31/lecture/988
- http://studfiles.net/preview/2592105/page:12/