Различные подходы к измерению количества информации в сообщении определяются различием подходов к определению самого понятия «информация».
Чтобы измерить что-либо, необходимо ввести единицу измерения. Минимальная единица измерения информации — бит. Смысл данной единицы также различен в рамках разных подходов к измерению информации.
Выделяют три подхода.
1. Неизмеримость информации в быту
Если в сообщении содержалось для вас что-то новое, то оно информативно. Но для другого человека в этом же сообщении нет ничего нового, для него оно не информативно. Это происходит оттого, что до получения данного сообщения знания каждого из нас были различны. Фактор субъективного восприятия сообщения делает невозможным количественную оценку информации в сообщении, т. е. если рассматривать количество полученной информации с точки зрения новизны для получателя, то измерить её невозможно.
2. Вероятностный, или содержательный подход
Попытаться объяснить данный подход можно, допустив,
что для каждого человека можно условно выделить (например, в виде окружности) область его знания. Всё, что будет находиться за пределами окружности, можно назвать информационной неопределенностью. Постепенно, в процессе обучения или иной деятельности происходит переход от незнания к знанию, т. е. неопределенность уменьшается. Именно такой подход к информации как мере уменьшения неопределенности знания позволяет ее количественно оценить (измерить).
Сообщение, уменьшающее неопределенность знания в 2 раза, несет один бит информации.
Например: при подбрасывании монеты может выпасть либо «орел», либо «решка». Это два возможных события. Они равновероятны. Сообщение о том, что произошло одно из двух равновероятных событий (например, выпала «решка»), уменьшает неопределенность нашего знания (перед броском монеты) в два раза.
Математики рассматривают идеальный вариант, что возможные события равновероятны. Если даже события неравновероятны, то возможен подсчет вероятности выпадения каждого события.
Под неопределенностью знания здесь понимают количество возможных событий, их может быть больше, чем два.
Например, количество оценок, которые может получить студент на экзамене, равно четырем. Сколько информации содержится в сообщении о том, что он получил «4»? Рассуждая, с опорой на приведенное выше определение, можем сказать, что если сообщение об одном из двух возможных событий несет 1 бит информации, то выбор одного из четырех возможных событии несет 2 бита информации. Можно прийти к такому выводу, пользуясь методом половинного деления. Сколько вопросов необходимо задать, чтобы выяснить необходимое, столько битов и содержит сообщение. Вопросы должны быть сформулированы так, чтобы на них можно было ответить «да» или «нет», тогда каждый из них будет уменьшать количество возможных событий в 2 раза.
Это формула Р. Хартли. Если р = 1/N — вероятность наступления каждого из N равновероятных событий, тогда формула Хартли записывается так:
i = log2(1/p) = log2p
Чтобы пользоваться рассмотренным подходом, необходимо вникать в содержание сообщения. Это не позволяет использовать данный подход для кодирования и передачи информации с помощью технических устройств.
3. Алфавитный подход к измерению информации
Подход основан на подсчете числа символов в сообщении. Этот подход не связывает количество информации с содержанием сообщения, позволяет реализовать передачу, хранение и обработку информации с помощью технических устройств, не теряя при этом содержания (смысла) сообщения.
Алфавит любого языка включает в себя конечный набор символов. Исходя из вероятностного подхода к определению количества информации, появление символов алфавита в тексте можно рассматривать как различные возможные события. Количество таких событий (символов) N называют мощностью алфавита. Тогда количество информации (, которое несет каждый из N символов, согласно вероятностному подходу определяется из формулы:
Количество символов в тексте из k символов:
Алфавитный подход является объективным способом измерения информации и используется в технических устройствах.
Переход к более крупным единицам измерения
Ограничения на максимальную мощность алфавита не существует, но есть алфавит, который можно считать достаточным (на современном этапе) для работы с информацией, как для человека, так и для технических устройств. Он включает в себя: латинский алфавит, алфавит языка страны, числа, спецсимволы — всего около 200 знаков. По приведенной выше таблице можно сделать вывод, что 7 битов информации недостаточно, требуется 8 битов, чтобы закодировать любой символ такого алфавита, 256 = 28. 8 бит образуют 1 байт. То есть для кодирования символа компьютерного алфавита используется 1 байт. Укрупнение единиц измерения информации аналогично применяемому в физике — используют приставки «кило», «мега», «гига». При этом следует помнить, что основание не 10, а 2.
1 Кб (килобайт) = 210 байт = 1024 байт,
1 Мб(мегабайт) = 210 Кб = 220 байт и т. д.
Умение оценивать количество информации в сообщении поможет определить скорость информационного потока по каналам связи. Максимальную скорость передачи информации по каналу связи называют пропускной способностью канала связи. Самым совершенным средством связи на сегодня являются оптические световоды. Информация передается в виде световых импульсов, посылаемых лазерным излучателем. У этих средств связи высокая помехоустойчивость и пропускная способность более 100Мбит/с.
studopedia.org — Студопедия.Орг — 2014-2019 год. Студопедия не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования (0.001 с) . 
Материал разработан на 2 спаренных урока.
Цели уроков: Сформировать у учащихся понимание вероятности, равновероятных событий и событий с различными вероятностями. Научить находить количество информации, используя вероятностный подход. Создать в Excel информационную модель для автоматизации процесса вычислений в задачах на нахождение количества информации, используя формулу Шеннона.
Требования к знаниям и умениям:
Учащиеся должны знать:
- какие события являются равновероятными, какие неравновероятными;
- как найти вероятность события;
- как найти количество информации в сообщении, что произошло одно из неравновероятных событий;
- как найти количество информации в сообщении, когда возможные события имеют различные вероятности реализации.
Учащиеся должны уметь:
- различать равновероятные и неравновероятные события;
- находить количество информации в сообщении, что произошло одно из равновероятных событий или одно из не равновероятных событий;
- создать информационную модель для автоматизации процесса решения задач на нахождение количества информации с помощью прикладных программ.
Оборудование: доска, компьютер, мультимедийный проектор, карточки с заданиями, карточки-памятки, справочный материал.
Урок 1. Вероятностный подход к определению количества информации. Формула Шеннона
Ход урока
I. Организационный момент.
II. Проверка домашнего задания.
III. Постановка цели урока.
Задача: Какое сообщение содержит большее количество информации?
- В библиотеке 8 шкафов. Книга нашлась в 3-м шкафу; (Отв.: 3 бит.)
- Вася получил за экзамен оценку 4 (по 5-бальной системе единицы не ставят). (Отв.: 2 бит.)
- Бабушка испекла 12 пирожков с капустой, 12 пирожков с повидлом. Маша съела один пирожок. (Отв.: 1 бит.)
- Бабушка испекла 8 пирожков с капустой, 16 пирожков с повидлом. Маша съела один пирожок.
Первые три варианта учащиеся решают без затруднения. События равновероятны, поэтому можно применить для решения формулу Хартли. Но третье задание вызывает затруднение. Делаются различные предположения. Роль учителя: подвести учащихся к осмыслению, что в четвертом варианте мы сталкиваемся с ситуацией, когда события неравновероятны. Не все ситуации имеют одинаковые вероятности реализации. Существует много таких ситуаций, у которых вероятности реализации различаются. Например, если бросают несимметричную монету или «правило бутерброда».
Сегодня на уроке мы должны ответить на вопрос: как вычислить количество информации в сообщении о неравновероятном событии.
IV. Объяснение нового материала.
Для вычисления количества информации в сообщении о неравновероятном событии используют следующую формулу: I=log2(1/p)
где I – это количество информации, р – вероятность события.
Вероятность события выражается в долях единицы и вычисляется по формуле: р=K/N,
где К – величина, показывающая сколько раз произошло интересующее нас событие, N – общее число возможных исходов какого-то процесса.
Вернемся к нашей задаче.
Пусть К1 – это количество пирожков с повидлом, К1=24
К2 – количество пирожков с капустой, К2=8
N – общее количество пирожков, N = К1 +К2=24+8=32
Вычислим вероятность выбора пирожка с разной начинкой и количество информации, которое при этом было получено.
Вероятность выбора пирожка с повидлом: р1=24/32=3/4=0,75.
Вероятность выбора пирожка с капустой: р2=8/32=1/4=0,25.
Обращаем внимание учащихся на то, что в сумме все вероятности дают 1.
Вычислим количество информации, содержащееся в сообщении, что Маша выбрала пирожок с повидлом: I1=log2(1/p1)= log2(1/0,75)= log21,3=1,15470 бит.
Вычислим количество информации, содержащееся в сообщении, если был выбран пирожок с капустой: I2=log2(1/p2)= log2(1/0,25)= log24=2 бит.
Пояснение: если учащиеся не умеют вычислять значение логарифмической функции, то можно использовать при решении задач этого урока следующие приемы:
- Ответы давать примерные, задавая ученикам следующий вопрос: «В какую степень необходимо возвести число 2, чтобы получилось число, стоящее под знаком логарифма?».
- Применить таблицу из задачника-практикума под редакцией Семакина И.Г. и др.
Приложение 1. «Количество информации в сообщении об одном из N равновероятных событий: I= log2N». (Приложение вы можете получить у автора статьи.)
При сравнении результатов вычислений получается следующая ситуация: вероятность выбора пирожка с повидлом больше, чем с капустой, а информации при этом получилось меньше. Это не случайность, а закономерность.
Качественную связь между вероятностью события и количеством информации в сообщении об этом событии можно выразить так: чем меньше вероятность некоторого события, тем больше информации содержит сообщение об этом событии.
Вернемся к нашей задаче с пирожками. Мы еще не ответили на вопрос: сколько получим информации при выборе пирожка любого вида?
Ответить на этот вопрос нам поможет формула вычисления количества информации для событий с различными вероятностями, которую предложил в 1948 г. американский инженер и математик К.Шеннон.
Если I-количество информации, N-количество возможных событий, рi — вероятности отдельных событий, где i принимает значения от 1 до N, то количество информации для событий с различными вероятностями можно определить по формуле:
можно расписать формулу в таком виде:
Рассмотрим формулу на нашем примере:
Теперь мы с вами можем ответить на вопрос задачи, которая была поставлена в начале урока. Какое сообщение содержит большее количество информации?
- В библиотеке 8 шкафов. Книга нашлась в 3-м шкафу; (Отв.: 3 бит.)
- Вася получил за экзамен 3 балла (по 5-бальной системе единицы не ставят). (Отв.: 2 бит.)
- Бабушка испекла 12 пирожков с капустой, 12 пирожков с повидлом. Маша съела один пирожок. (Отв.: 1 бит.)
- Бабушка испекла 8 пирожков с капустой, 16 пирожков с повидлом. Маша съела один пирожок. (Отв.: 0,815 бит.)
Ответ: в 1 сообщении.
Обратите внимание на 3 и 4 задачу. Сравните количество информации.
Мы видим, что количество информации достигает максимального значения, если события равновероятны.
Интересно, что рассматриваемые нами формулы классической теории информации первоначально были разработаны для технических систем связи, призванных служить обмену информацией между людьми. Работа этих систем определяется законами физики т.е. законами материального мира. Задача оптимизации работы таких систем требовала, прежде всего, решить вопрос о количестве информации, передаваемой по каналам связи. Поэтому вполне естественно, что первые шаги в этом направлении сделали сотрудники Bell Telephon Companie – X. Найквист, Р. Хартли и К. Шеннон. Приведенные формулы послужили К. Шеннону основанием для исчисления пропускной способности каналов связи и энтропии источников сообщений, для улучшения методов кодирования и декодирования сообщений, для выбора помехоустойчивых кодов, а также для решения ряда других задач, связанных с оптимизацией работы технических систем связи. Совокупность этих представлений, названная К. Шенноном “математической теорией связи”, и явилась основой классической теории информации. (Дополнительный материал можно найти на сайте http://polbu.ru/korogodin_information или прочитав книгу В.И. Корогодин, В.Л. Корогодина. Информация как основа жизни. Формула Шеннона.)
Можно ли применить формулу К. Шеннона для равновероятных событий?
Мы видим, что формула Хартли является частным случаем формулы Шеннона.
V. Закрепление изучаемого материала.
Задача: В корзине лежат 32 клубка красной и черной шерсти. Среди них 4 клубка красной шерсти.
Сколько информации несет сообщение, что достали клубок красной шерсти? Сколько информации несет сообщение, что достали клубок шерсти любой окраски?
Дано: Кк=4;N=32
Найти: Iк, I
Решение:
- Найдем количество клубков черной шерсти: Кч=N- Кк; Кч=32-4=28
- Найдем вероятность доставания клубка каждого вида: pк= Кк/N=4/32=1/8; pч= Кч/N=28/32=7/8;
- Найдем количество информации, которое несет сообщение, что достали клубок красной шерсти: Iк= log2(1/(1/ pк))= log2(1/1/8)= log28=3 бит
- Найдем количество информации, которое несет сообщение, что достали клубок шерсти любой окраски:
VI. Подведение итогов урока.
- Объясните на конкретных примерах отличие равновероятного события от неравновероятного?
- С помощью какой формулы вычисляется вероятность события.
- Объясните качественную связь между вероятностью события и количеством информации в сообщении об этом событии.
- В каких случаях применяется формула Шеннона для измерения количества информации.
- В каком случае количество информации о событии достигает максимального значения.
Урок 2. Применение ЭТ Excel для решения задач на нахождение количества информации
Пояснение: При решении задач на нахождение количества информации учащиеся не вычисляли значение логарифма, т.к. не знакомы с логарифмической функцией. Урок строился таким образом: сначала решались однотипные задачи с составлением формул, затем разрабатывалась табличная модель в Excel, где учащиеся делали вычисления. В конце урока озвучивались ответы к задачам.
Ход урока
I. Постановка целей урока
На этом уроке мы будем решать задачи на нахождение количества информации в сообщении о неравновероятных событиях и автоматизируем процесс вычисления задач данного типа.
Для решения задач на нахождение вероятности и количества информации используем формулы, которые вывели на прошлом уроке:
рi=Ki/N; Ii=log2(1/pi);
II. Решение задач.
Ученикам дается список задач, которые они должны решить.
Задачи решаются только с выводами формул, без вычислений.
В озере обитает 12500 окуней, 25000 пескарей, а карасей и щук по 6250. Какое количество информации несет сообщение о ловле рыбы каждого вида. Сколько информации мы получим, когда поймаем какую-нибудь рыбу?
Решение:
- Найдем общее количество рыбы: N= Ко+Кп+Кк+Кщ.
- Найдем вероятность ловли каждого вида рыбы: pо= Ко/N;pп= Кп/N;pк=pщ= Кк/N.
- Найдем количество информации о ловле рыбы каждого вида: Iо=log2( 1/pо);Iп=log2(1/pп);Iк=Iщ=log2(1/pк)
- Найдем количество информации о ловле рыбы любого вида: I=pо∙log2pо+pп∙log2pп+pк∙log2pк+pщ∙log2pщ
III. Объяснение нового материала.
Задается вопрос ученикам:
1. Какие трудности возникают при решении задач данного типа? (Отв.: Вычисление логарифмов).
2. Нельзя ли автоматизировать процесс решения данных задач? (Отв.: можно, т.к. алгоритм вычислений в этих задачах один и тот же).
3. Какие программы используются для автоматизации вычислительного процесса? (Отв.: ЭТ Excel).
Давайте попробуем сделать табличную модель для вычисления задач данного типа.
Нам необходимо решить вопрос, что мы будем вычислять в таблице. Если вы внимательно присмотритесь к задачам, то увидите, что в одних задачах надо вычислить только вероятность событий, в других количество информации о происходящих событиях или вообще количество информации о событии.
Мы сделаем универсальную таблицу, где достаточно занести данные задачи, а вычисление результатов будет происходить автоматически.
Структура таблицы обсуждается с учениками. Роль учителя обобщить ответы учащихся.
При составлении таблицы мы должны учитывать:
- Ввод данных (что дано в условии).
- Подсчет общего количества числа возможных исходов (формула N=K1+K2+…+Ki).
- Подсчет вероятности каждого события (формула pi= Кi/N).
- Подсчет количества информации о каждом происходящем событии (формула Ii= log2(1/pi)).
- Подсчет количества информации для событий с различными вероятностями (формула Шеннона).
Прежде чем демонстрировать заполнение таблицы, учитель повторяет правила ввода формул, функций, операцию копирования (домашнее задание к этому уроку).
При заполнении таблицы показывает как вводить логарифмическую функцию. Для экономии времени учитель демонстрирует уже готовую таблицу, а ученикам раздает карточки-памятки по заполнению таблицы.
Рассмотрим заполнение таблицы на примере задачи №1.
Рис. 1. Режим отображения формул
Рис. 2. Отображение результатов вычислений
Результаты вычислений занести в тетрадь.
Если в решаемых задачах количество событий больше или меньше, то можно добавить или удалить строчки в таблице.
VI. Практическая работа.
1. Сделать табличную модель для вычисления количества информации.
2. Используя табличную модель, сделать вычисления к задаче №2 (рис.3), результат вычисления занести в тетрадь.
3. Используя таблицу-шаблон, решить задачи №3,4 (рис.4, рис.5), решение оформить в тетради.
4. Сохранить таблицы в своих папках под именем «инф_вероятность».
В классе 30 человек. За контрольную работу по информатике получено 15 пятерок, 6 четверок, 8 троек и 1 двойка. Какое количество информации несет сообщение о том, что Андреев получил пятерку?
В коробке лежат кубики: 10 красных, 8 зеленых, 5 желтых, 12 синих. Вычислите вероятность доставания кубика каждого цвета и количество информации, которое при этом будет получено.
В непрозрачном мешочке хранятся 10 белых, 20 красных, 30 синих и 40 зеленых шариков. Какое количество информации будет содержать зрительное сообщение о цвете вынутого шарика?
VII. Подведение итогов урока.
Учитель оценивает работу каждого ученика. Оценивается не только практическая работа на компьютере, но и оформление решения задачи в тетради.
VIII. Домашняя работа.
1. Параграф учебника «Формула Шеннона», компьютерный практикум после параграфа.
2. Доказать, что формула Хартли – частный случай формулы Шеннона.
Литература:
- Соколова О.Л. «Универсальные поурочные разработки по информатике. 10-й класс.» – М.: ВАКО, 2007.
- Угринович Н.Д. «Информатика и ИКТ. Профильный уровень. 10 класс» — Бином, Лаборатория знаний, 2007 г.
- Семакин И.Г., Хеннер Е.К. «Информатика. Задачник – практикум.» 1 том, — Бином, Лаборатория знаний, 2008 г.
Содержательный (вероятностный) подход к измерению информации
Существует два подхода к измерению информации: содержательный (вероятностный) и объемный (алфавитный).
Процесс познания окружающего мира приводит к накоплению информации в форме знаний (фактов, научных теорий и т.д.). Получение новой информации приводит к расширению знания или к уменьшению неопределенности знаний. Если некоторое сообщение приводит к уменьшению неопределенности нашего знания, то можно говорить, что такое сообщение содержит информацию.
Пусть у нас имеется монета, которую мы бросаем. С равной вероятностью произойдет одно из двух возможных событий – монета окажется в одном из двух положений: «орел» или «решка». Можно говорить, что события равновероятны.
Перед броском существует неопределенность наших знаний (возможны два события), и, как упадет монета, предсказать невозможно. После броска наступает полная определенность, так как мы видим, что монета в данный момент находится в определенном положении (например, «орел»). Это сообщение приводит к уменьшению неопределенности наших знаний в два раза, так как до броска мы имели два вероятных события, а после броска – только одно, то есть в два раза меньше.
Чем больше неопределенна первоначальная ситуация (возможно большее количество информационных сообщений – например, бросаем не монету, а шестигранный кубик), тем больше мы получим новой информации при получении информационного сообщения (в большее количество раз уменьшится неопределенность знания).
Количество информацииможно рассматривать как меру уменьшения неопределенности знания при получении информационных сообщений.
Существует формула – главная формула информатики, которая связывает между собой количество возможных информационных сообщений N и количество информации I, которое несет полученное сообщение:
N = 2 I
За единицу количества информации принимается такое количество информации, которое содержится в информационном сообщении, уменьшающем неопределенность знания в два раза. Такая единица названа бит.
Если вернуться к опыту с бросанием монеты, то здесь неопределенность как раз уменьшается в два раза и, следовательно, полученное количество информации равно 1 биту.
2 = 2 1
Бит – наименьшая единица измерения информации.
С помощью набора битов можно представить любой знак и любое число. Знаки представляются восьмиразрядными комбинациями битов – байтами.
1байт = 8 битов = 2 3 битов
Байт– это 8 битов, рассматриваемые как единое целое, основная единица компьютерных данных.
Рассмотрим, каково количество комбинаций битов в байте.
Если у нас две двоичные цифры (бита), то число возможных комбинаций из них:
2 2 =4: 00, 01, 10, 11
Если четыредвоичные цифры (бита), то число возможных комбинаций:
2 4 =16: 0000, 0001, 0010, 0011,
0100, 0101, 0110, 0111,
1000, 1001, 1010, 1011,
1100, 1101, 1110, 1111
Так как в байте 8 бит (двоичных цифр), то число возможных комбинаций битов в байте:
2 8 =256
Таким образом, байт может принимать одно из 256 значений или комбинаций битов.
Для измерения информации используются более крупные единицы: килобайты, мегабайты, гигабайты, терабайты и т.д.
1 Кбайт = 2 10 байт = 1 024 байт
1 Мбайт = 2 20 байт = 2 10 Кбайт = 1 024 Кбайт = 1 048 576 байт
1 Гбайт = 2 30 байт = 1 024 Мбайт
1 Тбайт = 2 40 байт = 1 024 Гбайт
| Единицы измерения информации | ||||
| Название | Символ | Символ ГОСТ | Приставка | |
| Десятичная | Двоичная | |||
| байт | В | байт | 10 0 | 2 0 |
| килобайт | kB | Кбайт | 10 3 | 2 10 |
| мегабайт | MB | Мбайт | 10 6 | 2 20 |
| гигабайт | GB | Гбайт | 10 9 | 2 30 |
| терабайт | TB | Тбайт | 10 12 | 2 40 |
| петабайт | PB | Пбайт | 10 15 | 2 50 |
| эксабайт | EB | Эбайт | 10 18 | 2 60 |
| зетабайт | ZB | Збайт | 10 21 | 2 70 |
| йоттабайт | YB | Йбайт | 10 24 | 2 80 |
Проведем аналогию с единицами длины:
если 1 бит «соответствует» 1 мм, то:
1 байт – 10 мм = 1см;
1 Кбайт – 1000 см = 10 м;
1 Мбайт – 10 000 м = 10 км;
1 Гбайт – 10 000 км (расстояние от Москвы до Владивостока).
Рассмотрим следующие примеры:
страница учебника содержит приблизительно 3 Кбайта информации;
1 газета – 150 Кбайт.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: При сдаче лабораторной работы, студент делает вид, что все знает; преподаватель делает вид, что верит ему. 8446 —  | 6702 —
| 6702 —  или читать все.
или читать все.
193.124.117.139 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
2.3. Единицы количества информации: вероятностный и объемный подходы
Определить понятие «количество информации» довольно сложно. В решении этой проблемы существуют два основных подхода. Исторически они возникли почти одновременно. В конце 40-х годов XX века один из основоположников кибернетики американский математик Клод Шеннон развил вероятностный подход к измерению количества информации, а работы по созданию ЭВМ привели к «объемному» подходу.
Вероятностный подход
Рассмотрим в качестве примера опыт, связанный с бросанием правильной игральной .кости, имеющей N граней (наиболее распространенным является случай шестигранной кости: N = 6). Результаты данного опыта могут быть следующие: выпадение грани с одним из следующих знаков: 1,2. N.
Введем в рассмотрение численную величину, измеряющую неопределенность —энтропию(обозначим ее Н). Величины N и Н связаны между собой некоторой функциональной зависимостью:
а сама функция fявляется возрастающей, неотрицательной и определенной (в рассматриваемом нами примере) для N = 1, 2. 6.
Рассмотрим процедуру бросания кости более подробно:
1) готовимся бросить кость; исход опыта неизвестен, т.е. имеется некоторая неопределенность; обозначим ее H1;
2) кость брошена; информация об исходе данного опыта получена; обозначим количество этой информации через I;
3) обозначим неопределенность данного опыта после его осуществления через H2. За количество информации, которое получено в ходе осуществления опыта, примем разность неопределенностей «до» и «после» опыта:
Очевидно, что в случае, когда получен конкретный результат, имевшаяся неопределенность снята (Н2= 0), и, таким образом, количество полученной информации совпадает с первоначальной энтропией. Иначе говоря, неопределенность, заключенная в опыте, совпадает с информацией об исходе этого опыта. Заметим, что значение Н2 могло быть и не равным нулю, например, в случае, когда в ходе опыта следующей выпала грань со значением, большим «З».
Следующим важным моментом является определение вида функции fв формуле (1.1). Если варьировать число гранейNи число бросаний кости (обозначим эту величину черезМ),общее число исходов (векторов длины М, состоящих из знаков 1,2. N)будет равноNв степениМ:
Так, в случае двух бросаний кости с шестью гранями имеем: Х= 6 2 = 36. Фактически каждый исходХесть некоторая пара(X1, X2),гдеX1иX2 —соответственно исходы первого и второго бросаний (общее число таких пар —X).
Ситуацию с бросанием Мраз кости можно рассматривать как некую сложную систему, состоящую из независимых друг от друга подсистем — «однократных бросаний кости». Энтропия такой системы вМраз больше, чем энтропия одной системы (так называемый «принцип аддитивности энтропии»):
Данную формулу можно распространить и на случай любого N:
Прологарифмируем левую и правую части формулы (1.3): ln X = M ∙ ln N, М= ln X/1n M. Подставляем полученное дляMзначение в формулу (1.4):
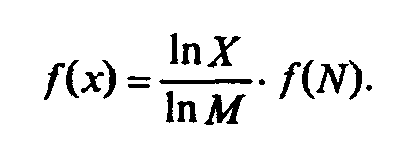
Обозначив через Кположительную константу , получим:f(X) = К ∙ lп Х,или, с учетом (1.1), H=K ∙ ln N.Обычно принимаютК= 1 / ln 2. Таким образом
Это — формула Хартли.
Важным при введение какой-либо величины является вопрос о том, что принимать за единицу ее измерения. Очевидно, Нбудет равно единице приN = 2.Иначе говоря, в качестве единицы принимается количество информации, связанное с проведением опыта, состоящего в получении одного из двух равновероятных исходов (примером такого опыта может служить бросание монеты при котором возможны два исхода: «орел», «решка»). Такая единица количества информации называется «бит».
Все Nисходов рассмотренного выше опыта являются равновероятными и поэтому можно считать, что на «долю» каждого исхода приходится однаN-ячасть общей неопределенности опыта: (log2N)1N.При этом вероятностьi-го исходаРi равняется, очевидно, 1/N.

Та же формула (1.6) принимается за меру энтропии в случае, когда вероятности различных исходов опыта неравновероятны(т.е.Рiмогут быть различны). Формула (1.6) называется формулой Шеннона.
В качестве примера определим количество информации, связанное с появлением каждого символа в сообщениях, записанных на русском языке. Будем считать, что русский алфавит состоит из 33 букв и знака «пробел» для разделения слов. По формуле (1.5)
Однако, в словах русского языка (равно как и в словах других языков) различные буквы встречаются неодинаково часто. Ниже приведена табл. 1.3 вероятностей частоты употребления различных знаков русского алфавита, полученная на основе анализа очень больших по объему текстов.
Воспользуемся для подсчета Нформулой (1.6);Н ≈ 4,72 бит. Полученное значениеН,как и можно было предположить, меньше вычисленного ранее. ВеличинаН, вычисляемая по формуле (1.5), является максимальным количеством информации, которое могло бы приходиться на один знак.
Таблица 1.3. Частотность букв русского языка
Содержательный (вероятностный) подход к измерению информации
Читайте также:
- A) Системный подход
- A.4.3 Подход к ранжированию
- BPR -революционный подход
- CPI/TQM-эволюционный подход
- Cпособ представления морфологической информации
- FPR_UNO.3 Скрытность без запроса информации
- I подход.Калькулирование полной себестоимости
- I Сложное предложение как синтаксическая единица. Различие подходов к определению сложного предложения
- I. Перехват информации
- II. Обоснование исходной геолого – промысловой информации.
- III. Внутренняя структура политического процесса с позиций отношений субъект объект, или субъект – субъект, изучался поведенческим подходом.
- IX. ФИНАНСИРОВАНИЕ МЕРОПРИЯТИЙ ПО ЗАЩИТЕ ИНФОРМАЦИИ
Существует два подхода к измерению информации: содержательный (вероятностный) и объемный (алфавитный).
Процесс познания окружающего мира приводит к накоплению информации в форме знаний (фактов, научных теорий и т.д.). Получение новой информации приводит к расширению знания или к уменьшению неопределенности знаний. Если некоторое сообщение приводит к уменьшению неопределенности нашего знания, то можно говорить, что такое сообщение содержит информацию.
Пусть у нас имеется монета, которую мы бросаем. С равной вероятностью произойдет одно из двух возможных событий – монета окажется в одном из двух положений: «орел» или «решка». Можно говорить, что события равновероятны.
Перед броском существует неопределенность наших знаний (возможны два события), и, как упадет монета, предсказать невозможно. После броска наступает полная определенность, так как мы видим, что монета в данный момент находится в определенном положении (например, «орел»). Это сообщение приводит к уменьшению неопределенности наших знаний в два раза, так как до броска мы имели два вероятных события, а после броска – только одно, то есть в два раза меньше.
Чем больше неопределенна первоначальная ситуация (возможно большее количество информационных сообщений – например, бросаем не монету, а шестигранный кубик), тем больше мы получим новой информации при получении информационного сообщения (в большее количество раз уменьшится неопределенность знания).
Количество информацииможно рассматривать как меру уменьшения неопределенности знания при получении информационных сообщений.
Существует формула – главная формула информатики, которая связывает между собой количество возможных информационных сообщений N и количество информации I, которое несет полученное сообщение:
N = 2 I
За единицу количества информации принимается такое количество информации, которое содержится в информационном сообщении, уменьшающем неопределенность знания в два раза. Такая единица названа бит.
Если вернуться к опыту с бросанием монеты, то здесь неопределенность как раз уменьшается в два раза и, следовательно, полученное количество информации равно 1 биту.
2 = 2 1
Бит – наименьшая единица измерения информации.
С помощью набора битов можно представить любой знак и любое число. Знаки представляются восьмиразрядными комбинациями битов – байтами.
1байт = 8 битов = 2 3 битов
Байт– это 8 битов, рассматриваемые как единое целое, основная единица компьютерных данных.
Рассмотрим, каково количество комбинаций битов в байте.
Если у нас две двоичные цифры (бита), то число возможных комбинаций из них:
2 2 =4: 00, 01, 10, 11
Объемный (алфавитный) подход к измерению информации
Существует два подхода к измерению информации: содержательный (вероятностный) и объемный (алфавитный).
Информация является предметом нашей деятельности: мы ее храним, передаем, принимаем, обрабатываем. Нам часто необходимо знать, достаточно ли места на носителе, чтобы разместить нужную нам информацию, сколько времени потребуется, чтобы передать информацию по каналу связи и т.п. Величина, которая нас в этих ситуациях интересует, называется объемом информации. В таком случае говорят об объемном подходе к измерению информации.
Для обмена информацией с другими людьми человек использует естественные языки (русский, английский, китайский и др.), то есть информация представляется с помощью естественных языков. В основе языка лежит алфавит, т.е. набор символов (знаков), которые человек различает по их начертанию. В основе русского языка лежит кириллица, содержащая 33 знака, английский язык использует латиницу (26 знаков), китайский язык использует алфавит из десятков тысяч знаков (иероглифов).
Наряду с естественными языками были разработаны формальные языки (системы счисления, язык алгебры, языки программирования и др.). Основное отличие формальных языков от естественных состоит в наличии строгих правил грамматики и синтаксиса.
Например, системы счисления можно рассматривать как формальные языки, имеющие алфавит (цифры) и позволяющие не только именовать и записывать объекты (числа), но и выполнять над ними арифметические операции по строго определенным правилам.
Некоторые языки используют в качестве знаков не буквы и цифры, а другие символы, например химические формулы, ноты, изображения элементов электрических или логических схем, дорожные знаки, точки и тире (код азбуки Морзе и др.).
Представление информации может осуществляться с помощью языков, которые являются знаковыми системами. Каждая знаковая система строится на основе определенного алфавита и правил выполнения операций над знаками.
Знаки могут иметь различную физическую природу. Например, для представления информации с использованием языка в письменной форме используются знаки, которые являются изображением на бумаге или других носителях; в устной речи в качестве знаков языка используются различные звуки (фонемы), а при обработке текста на компьютере знаки представляются в форме последовательностей электрических импульсов (компьютерных кодов).
При хранении и передаче информации с помощью технических устройств информация рассматривается как последовательность символов – знаков (букв, цифр, кодов цветов точек изображения и т.д.)
Набор символов знаковой системы (алфавит) можно рассматривать как различные возможные состояния (события).
Тогда, если считать, что появление символов в сообщении равновероятно, по формуле
N = 2 I
где N– это количество знаков в алфавите знаковой системы, можно рассчитать I – количество информации, которое несет каждый символ.
Информационная емкость знаков зависит от их количества в алфавите. Так, информационная емкость буквы в русском алфавите, если не использовать букву «ё», составляет:
32 = 2 I ,т.е.I = 5 битов
В латинском алфавите 26 букв. Информационная емкость буквы латинского алфавита также 5 битов.
На основании алфавитного подхода можно подсчитать количество информации в сообщении Ic, для этого необходимо умножить количество информации, которое несет один символ I, на количество символов K в сообщении:
Ic = I ´ K
Например, в слове «информатика» 11 знаков (К=11), каждый знак в русском алфавите несет информацию 5 битов (I=5), тогда количество информации в слове «информатика» Iс=5х11=55 (битов).
С помощью формулы N = 2 I можно определить количество информации, которое несет знак в двоичной знаковой системе: N=2 Þ 2=2 I Þ 2 1 =2 I Þ I=1 бит
Таким образом, в двоичной знаковой системе 1 знак несет 1 бит информации. При двоичном кодировании объем информации равен длине двоичного кода.
Интересно, что сама единица измерения количества информации бит (bit) получила свое название от английского словосочетания BInary digiТ, т.е. двоичная цифра.
Чем большее количество знаков содержит алфавит знаковой системы, тем большее количество информации несет один знак.
Дата добавления: 2014-01-20 ; Просмотров: 900 ; Нарушение авторских прав? ;
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Определение количества информации на основе вероятностного подхода
При определении количества информации на основе вероятностного подхода рассматриваем вероятность некоторого события как величину, которая может принимать значения от нуля до единицы. Вероятность невозможного события равна нулю (например: “завтра Солнце не взойдет над горизонтом”), вероятность достоверного события равна единице (например: “Завтра солнце взойдет над горизонтом”).
Вероятность некоторого события определяется путем многократных наблюдений (измерений, испытаний). Такие измерения называют статистическими. И чем большее количество измерений выполнено, тем точнее определяется вероятность события.
Математическое определение вероятности звучит так: вероятность равна отношению числа исходов, благоприятствующих данному событию, к общему числу равновозможных исходов.
Рассмотренная выше формула Хартли определяет количество необходимой информации для выявления определенного элемента множества при условии, что все элементы равновероятны. Однако может быть так, что какие-то элементы более вероятны (чаще встречаются), а какие-то меньше. Например, в русском языке буква «а» употребляется чаще, чем буква «ю».
Существует множество ситуаций, когда возможные события имеют различные вероятности реализации. Например, если монета несимметрична (одна сторона тяжелее другой), то при ее бросании вероятности выпадения «орла» и «решки» будут различаться.
Формулу для вычисления количества информации в случае различных вероятностей событий предложил К. Шеннон в 1948 году. В этом случае количество информации определяется по формуле:
(1),
где I — количество информации;
N — количество возможных событий;
рi — вероятность i-го события.
Например, пусть при бросании несимметричной четырехгранной пирамидки вероятности отдельных событий будут равны:
Тогда количество информации, которое мы получим после реализации одного из них, можно рассчитать по формуле (2.2):
I = -(l/2 log2l/2 + l/4 log2l/4 + l/8 log2l/8 + l/8 log2l/8) = (1/2 + 2/4 + 3/8 + 3/8) битов = 14/8 битов = 1,75 бита.
Этот подход к определению количества информации называется вероятностным.
Пример. На автобусной остановке останавливаются два маршрута автобусов: № 5 и № 7. Ученику дано задание: определить, сколько информации содержит сообщение о том, что к остановке подошел автобус № 5, и сколько информации в сообщении о том, что подошел автобус № 7.
Ученик провел исследование. В течение всего рабочего дня он подсчитал, что к остановке автобусы подходили 100 раз. Из них — 25 раз подходил автобус № 5 и 75 раз подходил автобус № 7. Сделав предположение, что с такой же частотой автобусы ходят и в другие дни, ученик вычислил вероятность появления на остановке автобуса № 5: p5= 25/100 = 1/4, и вероятность появления автобуса № 7: p7 = 75/100 = 3/4.
Отсюда, количество информации в сообщении об автобусе № 5 равно: i5 = log24 = 2 бита. Количество информации в сообщении об автобусе № 7 равно:
Исходя из этого, можно сделать качественный вывод: чем вероятность события меньше, тем больше количество информации в сообщении о нем.
Количество информации о достоверном событии равно нулю. Например, сообщение “Завтра наступит утро” является достоверным и его вероятность равна единице. Из формулы (3) следует: 2 i = 1/1 = 1. Отсюда, i = 0 бит.
Формула Хартли (1) является частным случаем формулы (3). Если имеется N равновероятных событий (результат бросания монеты, игрального кубика и т.п.), то вероятность каждого возможного варианта равна p = 1/N. Подставив в (3), снова получим формулу Хартли: 2 i = N. Если бы в примере 3 автобусы № 5 и № 7 приходили бы к остановке из 100 раз каждый по 50, то вероятность появления каждого из них была бы равна 1/2. Следовательно, количество информации в сообщении о приходе каждого автобуса равно i = log22 = 1 биту. Пришли к известному варианту информативности сообщения об одном из двух равновероятных событий.
Пример. Рассмотрим другой вариант задачи об автобусах. На остановке останавливаются автобусы № 5 и № 7. Сообщение о том, что к остановке подошел автобус № 5, несет 4 бита информации. Вероятность появления на остановке автобуса с № 7 в два раза меньше, чем вероятность появления автобуса № 5. Сколько бит информации несет сообщение о появлении на остановке автобуса № 7?
Запишем условие задачи в следующем виде:
Вспомним связь между вероятностью и количеством информации: 2 i = 1/p
Подставляя в равенство из условия задачи, получим:
Из полученного результата следует вывод: уменьшение вероятности события в 2 раза увеличивает информативность сообщения о нем на 1 бит. Очевидно и обратное правило: увеличение вероятности события в 2 раза уменьшает информативность сообщения о нем на 1 бит.
Контрольные вопросы:
1. Как измеряется информация при содержательном подходе?
2. Что такое алфавит?
3. Что называется мощностью алфавита?
4. Что называется объемом информации?
5. Как найти информационный вес символа?
6. Как рассчитать объем информации при равновероятносных событиях?
7. Как рассчитать объем информации при неравновероятносных событиях?
8. Что значит, информационный объем сообщения 1 бит?
9. Дайте определение понятию «энтропия» сообщения.
- http://xn--i1abbnckbmcl9fb.xn--p1ai/%D1%81%D1%82%D0%B0%D1%82%D1%8C%D0%B8/574162/
- http://studopedia.ru/10_209210_soderzhatelniy-veroyatnostniy-podhod-k-izmereniyu-informatsii.html
- http://studfiles.net/preview/956019/page:10/
- http://studopedia.su/10_152850_soderzhatelniy-veroyatnostniy-podhod-k-izmereniyu-informatsii.html
- http://megaobuchalka.ru/5/31484.html