Содержательный подход к измерению информации рассматривает информацию с точки зрения человека, как уменьшение неопределенности наших знаний.
Однако любое техническое устройство не воспринимает содержание информации.Поэтому в вычислительной технике используется другой подход к определению количества информации. Он называется алфавитным подходом.
При алфавитном подходе к определению количества информации отвлекаются от содержания информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Проще всего разобраться в этом на примере текста, написанного на каком-нибудь языке. Для нас удобнее, чтобы это был русский язык.
Все множество используемых в языке символов будем традиционно называть алфавитом. Обычно под алфавитом понимают только буквы, но поскольку в тексте могут встречаться знаки препинания, цифры, скобки, то мы их тоже включим в алфавит. В алфавит также следует включить и пробел, т.е. пропуск между словами.
Алфавит — множество символов, используемых при записи текста.
Мощность (размер) алфавита — полное количество символов в алфавите.
Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54.
Представьте себе, что текст к вам поступает последовательно, по одному знаку, словно бумажная ленточка, выползающая из телеграфного аппарата. Предположим, что каждый появляющийся на ленте символ с одинаковой вероятностью может быть любым символом алфавита. В действительности это не совсем так, но для упрощения примем такое предположение. В каждой очередной позиции текста может появиться любой из N символов. Тогда, согласно известной нам формуле N = 2 I (см. содержательный подход) каждый такой символ несет I бит информации, которое можно определить из решения уравнения: 2 I = 54. Получаем: I = 5.755 бит — такое количество информации несет один символ в русском тексте.
Чтобы найти количество информации во всем тексте, нужно посчитать число символов в нем и умножить на I.
Посчитаем количество информации на одной странице книги. Пусть страница содержит 50 строк. В каждой строке — 60 символов. Значит, на странице умещается 50×60=3000 знаков. Тогда объем информации будет равен: 5,755 х 3000 = 17265 бит.
При алфавитном подходе к измерению информации количество информации зависит не от содержания, а от размера текста и мощности алфавита.
Таким образом, алфавитный подход к измерению информации можно изобразить в виде таблицы:
При использовании двоичной системы (алфавит состоит из двух знаков: 0 и 1) каждый двоичный знак несет 1 бит информации.
Применение алфавитного подхода удобно, прежде всего, при использовании технических средств работы с информацией. В этом случае теряют смысл понятия «новые — старые», «понятные — непонятные» сведения.
Алфавитный подход является объективным способом измерения информации в отличие от субъективного содержательного подхода.
Удобнее всего измерять информацию, когда размер алфавита N равен целой степени двойки. Например, если N=16, то каждый символ несет 4 бита информации потому, что 2 4 = 16. А если N =32, то один символ «весит» 5 бит.
Ограничения на максимальный размер алфавита теоретически не существует. Однако есть алфавит, который можно назвать достаточным. С ним мы встречались при рассмотрении темы «Кодирование текствовой информации». Это алфавит мощностью 256 символов. В алфавит такого размера можно поместить все практически необходимые символы: латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания.
Поскольку 256 = 2 8 , то один символ этого алфавита «весит» 8 бит. Причем 8 бит информации — это настолько характерная величина, что ей даже присвоили свое название — байт.
1 байт = 8 бит.
Для измерения больших объемов информации используются следующие единицы:
1 Кб (один килобайт) = 1024 байт = 2 10 байт
1 Мб (один мегабайт) = 1024 Кб= 2 10 Кбайт = 2 20 байт
1 Гб (один гигабайт) = 1024 Мб= 2 10 Mбайт = 2 30 байт
1Тбайт (один терабайт)= 2 10 Гбайт = 1024Гбайт = 2 40 байт
1Пбайт(один петабайт)= 2 10 Тбайт = 1024Тбайт = 2 50 байт
1Эбайт(один экзабайт)= 2 10 Пбайт = 1024Пбайт = 2 60 байт
1Збайт(один зетабайт)= 2 10 Эбайт = 1024Эбайт = 2 70 байт
1Йбайт(один йотабайт)= 2 10 Збайт = 1024Збайт = 2 80 байт .
Алфавитный подход используется для измерения количества информации в тексте, представленном в виде последовательности символов некоторого алфавита. Такой подход не связан с содержанием текста. Количество информации в этом случае называется информационным объемом текста, который пропорционален размеру текста — количеству символов, составляющих текст. Иногда данный подход к измерению информации называют объемным подходом.
Каждый символ текста несет определенное количество информации. Его называют информационным весом символа. Поэтому информационный объем текста равен сумме информационных весов всех символов, составляющих текст.

Здесь предполагается, что текст — это последовательная цепочка пронумерованных символов. В формуле (1) i1 обозначает информационный вес первого символа текста, i2 — информационный вес второго символа текста и т.д.; K — размер текста, т.е. полное число символов в тексте.
Все множество различных символов, используемых для записи текстов, называется алфавитом. Размер алфавита — целое число, которое называется мощностью алфавита. Следует иметь в виду, что в алфавит входят не только буквы определенного языка, но все другие символы, которые могут использоваться в тексте: цифры, знаки препинания, различные скобки, пробел и пр.
Определение информационных весов символов может происходить в двух приближениях:
1) в предположении равной вероятности (одинаковой частоты встречаемости) любого символа в тексте;
2) с учетом разной вероятности (разной частоты встречаемости) различных символов в тексте.
Приближение равной вероятности символов в тексте
Если допустить, что все символы алфавита в любом тексте появляются с одинаковой частотой, то информационный вес всех символов будет одинаковым. Пусть N — мощность алфавита. Тогда доля любого символа в тексте составляет 1/N-ю часть текста. По определению вероятности (см. “Измерение информации. Содержательный подход”  ) эта величина равна вероятности появления символа в каждой позиции текста:
) эта величина равна вероятности появления символа в каждой позиции текста:
Согласно формуле К.Шеннона (см. “Измерение информации. Содержательный подход” ), количество информации, которое несет символ, вычисляется следующим образом:
Следовательно, информационный вес символа (i) и мощность алфавита (N) связаны между собой по формуле Хартли (см. “Измерение информации. Содержательный подход” )
Зная информационный вес одного символа (i) и размер текста, выраженный количеством символов (K), можно вычислить информационный объем текста по формуле:
Эта формула есть частный вариант формулы (1), в случае, когда все символы имеют одинаковый информационный вес.

Из формулы (2) следует, что при N = 2 (двоичный алфавит) информационный вес одного символа равен 1 биту.
С позиции алфавитного подхода к измерению информации 1 бит — это информационный вес символа из двоичного алфавита.
Более крупной единицей измерения информации является байт.
1 байт — это информационный вес символа из алфавита мощностью 256.
Поскольку 256 = 2 8 , то из формулы Хартли следует связь между битом и байтом:
Отсюда: i = 8 бит = 1 байт
Для представления текстов, хранимых и обрабатываемых в компьютере, чаще всего используется алфавит мощностью 256 символов. Следовательно,
1 символ такого текста “весит” 1 байт.
Помимо бита и байта, для измерения информации применяются и более крупные единицы:
1 Кб (килобайт) = 2 10 байт = 1024 байта,
1 Мб (мегабайт) = 2 10 Кб = 1024 Кб,
1 Гб (гигабайт) = 2 10 Мб = 1024 Мб.
Приближение разной вероятности встречаемости символов в тексте
В этом приближении учитывается, что в реальном тексте разные символы встречаются с разной частотой. Отсюда следует, что вероятности появления разных символов в определенной позиции текста различны и, следовательно, различаются их информационные веса.
Статистический анализ русских текстов показывает, что частота появления буквы “о” составляет 0,09. Это значит, что на каждые 100 символов буква “о” в среднем встречается 9 раз. Это же число обозначает вероятность появления буквы “о” в определенной позиции текста: po = 0,09. Отсюда следует, что информационный вес буквы “о” в русском тексте равен:

Самой редкой в текстах буквой является буква “ф”. Ее частота равна 0,002. Отсюда:

Отсюда следует качественный вывод: информационный вес редких букв больше, чем вес часто встречающихся букв.
Как же вычислить информационный объем текста с учетом разных информационных весов символов алфавита? Делается это по следующей формуле:

Здесь N — размер (мощность) алфавита; nj — число повторений символа номер j в тексте; ij — информационный вес символа номер j.
Методические рекомендации
Алфавитный подход в курсе информатики основой школы
В курсе информатики в основной школе знакомство учащихся с алфавитным подходом к измерению информации чаще всего происходит в контексте компьютерного представления информации. Основное утверждение звучит так:
Количество информации измеряется размером двоичного кода, с помощью которого эта информация представлена
Поскольку любые виды информации представляются в компьютерной памяти в форме двоичного кода, то это определение универсально. Оно справедливо для символьной, числовой, графической и звуковой информации.

Один знак (разряд) двоичного кода несет 1 бит информации.
При объяснении способа измерения информационного объема текста в базовом курсе информатики данный вопрос раскрывается через следующую последовательность понятий: алфавит — размер двоичного кода символа — информационный объем текста.
Логика рассуждений разворачивается от частных примеров к получению общего правила. Пусть в алфавите некоторого языка имеется всего 4 символа. Обозначим их: ,
,  ,
,  ,
,  . Эти символы можно закодировать с помощью четырех двухразрядных двоичных кодов: — 00, — 01, — 10, — 11. Здесь использованы все варианты размещений из двух символов по два, число которых равно 2 2 = 4. Отсюда делается вывод: информационный вес символа из 4-символьного алфавита равен двум битам.
. Эти символы можно закодировать с помощью четырех двухразрядных двоичных кодов: — 00, — 01, — 10, — 11. Здесь использованы все варианты размещений из двух символов по два, число которых равно 2 2 = 4. Отсюда делается вывод: информационный вес символа из 4-символьного алфавита равен двум битам.
Следующий частный случай — 8-символьный алфавит, каждый символ которого можно закодировать 3-разрядным двоичным кодом, поскольку число размещений из двух знаков группами по 3 равно 2 3 = 8. Следовательно, информационный вес символа из 8-символьного алфавита равен 3 битам. И т.д.
Обобщая частные примеры, получаем общее правило: с помощью b-разрядного двоичного кода можно закодировать алфавит, состоящий из N = 2 b — символов.
Пример 1. Для записи текста используются только строчные буквы русского алфавита и “пробел” для разделения слов. Какой информационный объем имеет текст, состоящий из 2000 символов (одна печатная страница)?
Решение. В русском алфавите 33 буквы. Сократив его на две буквы (например, “ё” и “й”) и введя символ пробела, получаем очень удобное число символов — 32. Используя приближение равной вероятности символов, запишем формулу Хартли:
Отсюда: i = 5 бит — информационный вес каждого символа русского алфавита. Тогда информационный объем всего текста равен:
I = 2000 · 5 = 10 000 бит
Пример 2. Вычислить информационный объем текста размером в 2000 символов, в записи которого использован алфавит компьютерного представления текстов мощностью 256.
Решение. В данном алфавите информационный вес каждого символа равен 1 байту (8 бит). Следовательно, информационный объем текста равен 2000 байт.
В практических заданиях по данной теме важно отрабатывать навыки учеников в пересчете количества информации в разные единицы: биты — байты — килобайты — мегабайты — гигабайты. Если пересчитать информационный объем текста из примера 2 в килобайты, то получим:
2000 байт = 2000/1024  1,9531 Кб
1,9531 Кб
Пример 3. Объем сообщения, содержащего 2048 символов, составил 1/512 часть мегабайта. Каков размер алфавита, с помощью которого записано сообщение?
Решение. Переведем информационный объем сообщения из мегабайтов в биты. Для этого данную величину умножим дважды на 1024 (получим байты) и один раз — на 8:
I = 1/512 · 1024 · 1024 · 8 = 16 384 бита.
Поскольку такой объем информации несут 1024 символа (К), то на один символ приходится:
Отсюда следует, что размер (мощность) использованного алфавита равен 2 16 = 65 536 символов.
Объемный подход в курсе информатики в старших классах
Изучая информатику в 10–11-х классах на базовом общеобразовательном уровне, можно оставить знания учащихся об объемном подходе к измерению информации на том же уровне, что описан выше, т.е. в контексте объема двоичного компьютерного кода.
При изучении информатики на профильном уровне объемный подход следует рассматривать с более общих математических позиций, с использованием представлений о частотности символов в тексте, о вероятностях и связи вероятностей с информационными весами символов.
Знание этих вопросов оказывается важным для более глубокого понимания различия в использовании равномерного и неравномерного двоичного кодирования (см. “Кодирование информации” ), для понимания некоторых приемов сжатия данных (см. “Сжатие данных” ) и алгоритмов криптографии (см. “Криптография” ).
Пример 4. В алфавите племени МУМУ всего 4 буквы (А, У, М, К), один знак препинания (точка) и для разделения слов используется пробел. Подсчитали, что в популярном романе “Мумука” содержится всего 10 000 знаков, из них: букв А — 4000, букв У — 1000, букв М — 2000, букв К — 1500, точек — 500, пробелов — 1000. Какой объем информации содержит книга?
Решение. Поскольку объем книги достаточно большой, то можно допустить, что вычисленная по ней частота встречаемости в тексте каждого из символов алфавита характерна для любого текста на языке МУМУ. Подсчитаем частоту встречаемости каждого символа во всем тексте книги (т.е. вероятность) и информационные веса символов


Общий объем информации в книге вычислим как сумму произведений информационного веса каждого символа на число повторений этого символа в книге:
Определение количества информации в сообщении
Все мы привыкли к тому, что все вокруг можно измерить. Мы можем определить массу посылки, длину стола, скорость движения автомобиля. Но как определить количество информации, содержащееся в сообщении? Ответ на вопрос в статье.
Итак, давайте для начала выберем сообщение. Пусть это будет «Принтер — устройство вывода информации.«. Наша задача — определить, сколько информации содержится в данном сообщении. Иными словами — сколько памяти потребуется для его хранения.
Определение количества информации в сообщении
Для решения задачи нам нужно определить, сколько информации несет один символ сообщения, а потом умножить это значение на количество символов. И если количество символов мы можем посчитать, то вес символа нужно вычислить. Для этого посчитаем количество различных символов в сообщении. Напомню, что знаки препинания, пробел — это тоже символы. Кроме того, если в сообщении встречается одна и та же строчная и прописная буква — мы считаем их как два различных символа. Приступим.
В слове Принтер 6 различных символов (р встречается дважды и считается один раз), далее 7-й символ пробел и девятый — тире. Так как пробел уже был, то после тире мы его не считаем. В слове устройство 10 символов, но различных — 7, так как буквы с, т и о повторяются. Кроме того буквы т и р уже была в слове Принтер. Так что получается, что в слове устройство 5 различных символов. Считая таким образом дальше мы получим, что в сообщении 20 различных символов.
Далее вспомним формулу, которую называют главной формулой информатики:
Подставив в нее вместо N количество различных символов, мы узнаем, сколько информации несет один символ в битах. В нашем случае формула будет выглядеть так:
Вспомним степени двойки и поймем, что i находится в диапазоне от 4 до 5 (так как 2 4 =16, а 2 5 =32). А так как бит — минимальная единица измерения информации и дробным быть не может, то мы округляем i в большую сторону до 5. Иначе, если принять, что i=4, мы смогли бы закодировать только 2 4 =16 символов, а у нас их 20. Поэтому получаем, что i=5, то есть каждый символ в нашем сообщении несет 5 бит информации.
Осталось посчитать сколько символов в нашем сообщении. Но теперь мы будем считать все символы, не важно повторяются они или нет. Получим, что сообщение состоит из 39 символов. А так как каждый символ — это 5 бит информации, то, умножив 5 на 39 мы получим:
5 бит x 39 символов = 195 бит
Это и есть ответ на вопрос задачи — в сообщении 195 бит информации. И, подводя итог, можно написать алгоритм нахождения объема информации в сообщении:
- посчитать количество различных символов.
- подставив это значение в формулу 2i=N найти вес одного символа (округлив в большую сторону)
- посчитать общее количество символов и умножить это число на вес одного символа.
Алфавитный подход к определению количества информации
- li» data-url=»/api/sort/PersonaCategory/list_order» >
- HTML Academy (1)
- ЭО и ДОТ (2)
- Уроки (2)
- Информатика 5 класс (5)
- Информатика 6 класс (5)
- Информатика 7 класс (6)
- КИТ (7)
- Инструкции (2)
- Рабочие документы (1)
- Правоустанавливающие документы (3)
Алфавитный подход к определению количества информации
Алфавитный подход к определению количества информации
Цели урока:
1) Обучающая: рассмотреть алфавитный подход к измерению количества информации, научиться вычислять количество информации с точки зрения алфавитного подхода.
2) Развивающая: развитие у учащихся самостоятельности и познавательной активности.
3) Воспитывающая: воспитывать дисциплинированность, аккуратность, собранность.
Литература:
- Угринович Н. Д. «Информатика 8 класс»,
- Заславская О. Ю., Левченко И. В. «Информатика: весь курс».
1) Угринович Н. Д. «Информатика 8 класс».
Тип урока: ознакомление с новым материалом
План урока:
- Организационный этап.
- Актуализация знаний.
- Подготовка учащихся к усвоению нового материала.
- Этап получения новых знаний.
- Этап обобщения и закрепления нового материала.
- Рефлексия.
- Заключительный этап.
Ход урока
- Организационный этап.
Здравствуйте. Прежде чем мы приступим к уроку, хотелось бы, чтобы каждый из вас настроился на рабочий лад.
- Актуализация знаний.
- В чём заключается содержательный подход к измерению информации? (Количество информации – мера уменьшения неопределённости знаний при получении информационных сообщений.)
- Какую минимальную единицу информации используют для измерения количества информации? (Бит)
- Какую формулу используют для определения количества информации ? (Формулу Хартли)
- Производится бросание симметричной четырехгранной пирамидки. Какое количество информации мы получаем в зрительном сообщении о ее падении на одну из граней? (2 бита)
- Из непрозрачного мешочка вынимают шарики с номерами и известно, что информационное сообщение о номере шарика несет 5 битов информации. Определите количество шариков в мешочке. (35)
- Этап получения новых знаний.
Содержательный подход к измерению информации рассматривает информацию с точки зрения человека, как уменьшение неопределенности наших знаний.
Однако любое техническое устройство не воспринимает содержание информации. Поэтому в вычислительной технике используется другой подход к определению количества информации. Он называется алфавитным подходом.
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Проще всего разобраться в этом на примере текста, написанного на каком-нибудь языке. Для нас удобнее, чтобы это был русский язык.
Все множество используемых в языке символов будем традиционно называть алфавитом. Обычно под алфавитом понимают только буквы, но поскольку в тексте могут встречаться знаки препинания, цифры, скобки, то мы их тоже включим в алфавит. В алфавит также следует включить и пробел, т.е. пропуск между словами.
Алфавит – это множество символов, используемых при записи текста.
Мощность (размер) алфавита – это полное количество символов в алфавите.
Мощность алфавита обозначается буквой N.
- мощность алфавита из русских букв равна 33;
- мощность алфавита из латинских букв – 26;
- мощность алфавита текста набранного с клавиатуры равна 256 (строчные и прописные латинские и русские буквы, цифры, знаки арифметических операций, скобки, знаки препинания и т.д.);
- мощность двоичного алфавита равна 2.
При алфавитном подходе считается, что каждый символ текста имеет информационную емкость. Информационная емкость знака зависит от мощности алфавита.
Алфавит, с помощью которого записано сообщение состоит из N знаков. В простейшем случае, когда длина кода сообщения составляет один знак, отправитель может послать одно из N возможных сообщений, которое будет нести количество информации I.
Тогда в формуле
N – количество знаков в алфавите знаковой системы, I – количество информации, которое несет каждый знак.
Например, из формулы можно определить количество информации, которое несет знак в двоичной знаковой системе
Информационная емкость знака двоичной знаковой системы составляет 1 бит.
Задача 1. Определите, какое количество информации несет буква русского алфавита (без буквы ё).
Буква русского алфавита несет 5 битов информации.
Формула связывает между собой количество возможных событий и количество информации, которое несёт полученное сообщение. В рассматриваемой ситуации N – это количество знаков в алфавите, знаковой системы, а I – количество информации, которое несёт один знак.
Сообщение состоит из последовательности знаков, каждый из которых несет определенное количество информации.
Количество информации в сообщении можно посчитать, умножив количество информации, которое несет один знак на количество знаков в сообщении.
где – количество информации в сообщении
— количество информации, которое несет один знак
– количество знаков в сообщении
Давайте решим с вами задачу.
Задача 2. Какое количество информации содержит слово «ПРИВЕТ», если считать, что алфавит состоит из 32 букв?
Решение. Что нам требуется найти в данной задаче? Нам нужно найти какое количество информации содержит слово «ПРИВЕТ».
Что нам для этого дано?
Дано: количество знаков в сообщение и мощность алфавита.
Количество знаков в сообщении равно 6, а мощность данного алфавита равна 32.
Что нам нужно найти? Нам нужно найти какое количество информации содержит слово «ПРИВЕТ».
Посмотрим на наше сообщение, оно содержит несколько знаков, значит для того чтобы найти количество информации нашего сообщения, нам нужно умножив количество информации, которое несет один знак, на количество знаков в сообщении, т.е. воспользоваться формулой «и» суммарное равно «и» умножить на «к».
Но мы еще не можем воспользоваться формулой, т.к. не знаем какое количество информации несет один знак. Для этого воспользуемся формулой Хартли. Сообщение записано с помощью алфавита, мощность которого равна 32, т.е. N равно 32. Мы получили уравнение. Решив это уравнение, мы получили, что количество информации, которое несет один знак нашего алфавита, равно 5 бит. Зная количество информации, которое несет один знак нашего алфавита, и количество знаков в сообщении, мы можем найти какое количество информации содержит наше сообщение.
Итак, наше сообщение содержит 30 бит.
- Этап обобщения и закрепления нового материала.
1) Какое количество информации содержит слово «ИНФОРМАТИКА», если считать, что алфавит состоит из 32 букв? (55 битов)
2) Определить количество информации, содержащееся в слове из 10 символов, если известно, что мощность алфавита равна 32 символам. (50 бит)
3) Сколько бит информации содержится в сообщении, состоящем из 5 символов, при использовании алфавита, состоящего из 64 символов. (6 битов)
4) Определить информативность сообщения «А + В = С», если для описания математических формул необходимо воспользоваться 64-символьным алфавитом. (30 бит)
5) Для представления числовых данных используют 16-ричный алфавит, включающий знаки математических действий. Сколько битов информации содержит выражение «32 * 5 = 160»? (32 бита)
6) Практическая работа №2. «Тренировка ввода текстовой и числовой информации с помощью клавиатурного тренажера»
Алфавитный подход.
Слово предоставляется группе №3
В3.
1.В чем заключается алфавитный подход к определению количества информации?
Для человека количество информации определяется на основе уменьшения неопределенности наших знаний, а компьютер не понимает содержание и новизну. Информация рассматривается им как последовательность букв, цифр, кодов цветов точек изображения и т.д. Это важно для хранения и передачи информации техническими устройствами.
2. Как посчитать количество информации в сообщении с помощью алфавитного подхода?
Через количество символов с учетом информационного веса символов.
3. Почему информационная емкость русской буквы а больше информационной ёмкости английской буквы?
Потому, что в русском алфавите букв больше, чем в английском. Число равновероятных событий появления русской буквы больше, значит и само её появление несет больше информации
4. Пусть две книги на русском и китайском языках содержат одинаковое количество знаков. В какой книге содержится большее количество информации с точки зрения алфавитного подхода?
Ответ: в китайской.
Учитель: Заполняем опорный конспект, отвечая на вопросы:
5. Сколько битов информации несет одна буква русского алфавита? Считать появление символов в сообщении равновероятным.______________________________________________________________________________________
6. Как подсчитать количество информации в слове записанном на русском языке?
7. Пусть две книги на русском и китайском языках содержат одинаковое количество знаков. В какой книге содержится большее количество информации с точки зрения алфавитного подхода?
Учитель выставляет оценки за работу в группах.
Единицы измерения информации
Какие единицы измерения вы знаете?
Ученик: минимальная единица измерения информации 1 бит. Так как «алфавит компьютера» (число символов на клавиатуре) составляет примерно 256 символов, то 1 символ составляет 8 бит информации (2 8 =256).
1 байт=2 3 =8 бит
Учитель: Более крупные единицы измерения информации:
1Кбайт (килобайт)=2 10 байт=1024 байт
1Мбайт (мегабайт)=2 10 Кбайт=1024 Кбайт=2 20 байт
1Гбайт (гигабайт)=2 10 Мбайт=1024 Мбайт=2 30 байт
1Тбайт (терабайт)=2 10 Гбайт=1024 Гбайт=2 40 байт
1Пбайт (петабайт)=2 10 Тбайт=1024 Тбайт=2 50 байт
Итак, количество информации, которое содержит сообщение, закодированное с помощью знаковой системы, равно количеству информации, которое несет один знак, умноженному на количество знаков в сообщении.
Формулы Хартли и Шеннона.
Учитель: Как определить полученное количество информации за один бросок игрального кубика?
У куба 6 граней, значит требуется решить показательное уравнение 2 I =6. Это можно сделать, используя понятие логарифма. Напомню, что логарифмом называют показатель степени I, в которую нужно возвести основание логарифма (2) чтобы получить заданное число N. Log26 ≈2,6 бит. Значит за один бросок мы получим 2, 6 бит информации.
1. Для равновероятных событий расчетная формула количества информации имеет вид: N=2 I или I =log2 N (формула оценки сообщений предложена в 1928 году Р. Хартли).
2. Иногда формула Хартли записывается иначе. Так как наступление каждого из N возможных событий имеет одинаковую вероятность P=1/N, то N = 1/P и формула имеет вид:
3. Существуют множества ситуаций, когда возможные события имеют различные вероятности реализации. Например, если монета не симметрична (одна сторона тяжелее другой), то при её бросании вероятности выпадения «орла» и «решки» будут различаться.
Формулу для вычисления количества информации в случае различных вероятностей событий предложил К.Шеннон в 1948 году. В этом случае количество информации определяется по формуле:
pi log 2 pi, где I –количество информации, N –количество возможных событий, pi –вероятности отдельных событий. Вероятность события pi=1/N.
Поясним формулу на примере:
Пусть при бросании несимметричной четырехгранной пирамидки вероятности отдельных событий будут равны:
Тогда, количество информации, которое мы получим после реализации одного из событий можно рассчитать по формуле:
I= — (1/2•log21/2 + 1/4•log21/4 + 1/8•log21/8 + 1/8•log21/8) = (1/2 + 2/4 + 3/8 + 3/8) битов =14/8 битов »1,75 бита.
Этот подход к определению количества информации называется вероятностным.
Выполнить задания №8,9 ОК.
8. Сравните количество получаемой информации при бросании симметричной пирамидки и несимметричной.
Итак, количество информации, которое мы получаем достигает максимального значения, если события равновероятны. (при бросании несимметричной четырехгранной пирамидки (1, 75 бита) – события не равновероятны, при бросании симметричной (2 бита) – события равновероятны)
9. Какое количество информации получит второй игрок в игре «Угадай число», если первый загадал число: 32, 128?___________________________________________________________________________________________
3. Практическая работа: (№2.3, стр. 82)
Вычислить с помощью электронного калькулятора Wise Calkulator количество информации, которое будет получено:
v При бросании симметричного шестигранного кубика;
v При игре в рулетку с 72 секторами;
v При игре в шахматы игроком за черных после первого хода белых, если считать все ходы равновероятными.
v При игре в шашки.
Ответы учащиеся записывают в тетрадь.
Ответ: 2, 58 бита, 6, 17 бита, 4, 32 бита. 2, 80 бита.
4. Решение задач.
Задача 1( №2.7 практикум Угринович стр.37)
Заполнить пропуски числами:
Чтобы перевести меньшую единицу числа в большую ( из Мб в Гб) надо разделить его на 1024, чтобы перевести большую единицу измерения в меньшую (из Мб в Кб) надо умножить на 1024.
1536 Мб=1536:1024 Гб=1,5 Гб
1536 Мб= 1536*1024 Кб=1 572 864 Кб
Д)512 Кб=2_ байт=2_ бит
512 Кб= 512*1024 байт=524288 байт или 2 9 *2 10 =2 19 байт
2 19 байт=2 19 *2 3 бит=2 22 бит, так как в 1 байте 8 бит или 2 3
Найти х из следующих соотношений:
Для сравнения двух частей надо обе части перевести в одну единицу измерения, лучше известную, т.е.32 Мб переведем в биты. Переведем сначала в байты.
32 Мб * 2 20 байт =2 5 *2 20 байт=2 25 байт.
Затем переведем в биты: 2 25 *2 3 бит=2 28 бит
Преобразуем левую часть в степень двойки: 2 4х бит=2 28 бит,значитх=7
Переведем Гб в Кбайты. 1ГБ=2 20 Кбайт,значит
16 Гб= 16*2 20 Кбайт=2 4 *2 20 Кбайт=2 24 Кбайт.Теперь переведем в степень 2 левую часть
2 3х Кб= 2 24 Кбайт,значитх=8
Пользователь компьютера, хорошо владеющий навыками ввода информации с клавиатуры может вводить в минуту 100 знаков. Мощность алфавита, используемого в компьютере равна 256. Какое количество информации в байтах может ввести пользователь за 1 минуту.
Решение: так как мощность алфавита ( количество символов в алфавите) равно 256, то длину кода одного символа легко посчитать, надо решить уравнение 2 x =256, где х=8, так как 1 байт= 8 бит, то 8*100=800 бит информации, или 100 байт за минуту будет введено.
Задача 4. В барабане для розыгрыша лотереи находится 32 шара. Сколько информации содержит сообщение о первом выпавшем номере (например, выпал номер 15)?
т.к. вытаскивание любого из шаров равновероятно, то количество информации вычисляется по формуле 2 I =N, где I – количество информации, а N – количество шаров. Тогда 2 I =32, отсюда I = 5 бит.
Задача 5. Группа школьников пришла в бассейн, в котором 4 дорожки для плавания. Тренер сообщил, что группа будет плавать на дорожке номер 3. Сколько информации получили школьники из этого сообщения?
Поскольку выбор одной дорожки из 4-х равновероятен, то количество информации определяется по формуле: 2 I =N, где I – количество информации, а N=4 – количество дорожек. Тогда 2 I =4, отсюда I=2 бита.
Задача 6. В корзине лежат 8 шаров. Все шары разного цвета. Сколько информации несет сообщение о том, что из корзины достали красный шар?
Поскольку все шары разного цвета, то вытаскивание одного шара из восьми равновероятно. Количество информации определяется по формуле: 2 I =N, где I – количество информации, а N=8 – количество шаров. Тогда 2 I =8, отсюда I=3 бита.
Задача 6. Была получена телеграмма: «Встречайте, вагон 7». Известно, что в составе поезда 16 вагонов. Какое количество информации было получено?
Поскольку номер вагона равновероятно может быть выбран из 16 вагонов, то количество информации определяется по формуле: 2 I =N, где I – количество информации, а N=16 – количество вагонов. Тогда 2 I =16, отсюда I=4 бита.
Задача 7. При угадывании целого числа в некотором диапазоне было получено 6 бит информации. Сколько чисел содержит этот диапазон?
Поскольку выбор числа равновероятен из заданного диапазона, то количество информации определяется по формуле 2 I =N, где I=6 бит, а N – количество чисел в искомом интервале. Отсюда: 2 6 =N, N=64.
Задача 8. Сообщение о том, что ваш друг живет на 10 этаже, несет 4 бита информации. Сколько этажей в доме?
Поскольку появление в сообщении номера этажа равновероятно из общего числа этажей в доме, то количество информации определяется по формуле: 2 I =N, где I = 4 – количество информации, N – число этажей в доме. Отсюда: 2 4 =N, N=16.
Задача 9. Какое количество информации несет сообщение: «Встреча назначена на сентябрь».
Поскольку появление в сообщении месяца сентябрь равновероятно из 12 месяцев, то количество информации определяется по формуле: 2 I =N, где I – количество информации, N – количество месяцев. Отсюда: 2 I =12, I=log212≈3.584962501 бит.
Задача 10.Какое количество информации несет сообщение о том, что встреча назначена на 15 число?
Поскольку появление в сообщении определенного числа равновероятно из общего числа дней в месяце, то количество информации определяется по формуле: 2 I =N, где I – количество информации, N=31 – количество дней в месяце. Отсюда: 2 I =31, I=log231≈4.954196310 бит.
5. Подведение итогов, домашнее задание:
Учитель подводит итог урока, выставляются оценки.
Итак, подводя итог выше сказанному, можно сказать, что математическая теория информациине охватывает всего богатства содержания информации, поскольку она отвлекается от содержательной (смысловой, семантической) стороны сообщения. С точки зрения этой теории фраза из 100 слов, взятая из газеты, пьесы Шекспира или теории Эйнштейна, имеет приблизительно одинаковое количество информации. Советский математик Ю. А. Шрейдер оценивал информацию по увеличению объема знаний у человека под воздействием информационного сообщения. Академик А.А. Харкевич измерял содержательность информации по увеличению вероятности достижения цели после получения информации человеком или машиной. В компьютере применяется алфавитный подход к измерению информации.
1. учить конспект.
2. Учебник Угриновича стр. 74-82.
3. Уметь отвечать на вопросы после каждого параграфа.
4. № 2.4, 2.5 (учебник, стр. 82).
5. повторить изученное, подготовиться к контрольной работе.
- Угринович Н.Д. Информатика и информационные технологии. Учебник для 10-11 классов. – М.:БИНОМ. Лаборатория знаний, 2003. с. 74-82.
- Шауцукова Л.З. Информатика: Учебн. Пособие для 10-11 кл. общеобразоват. Учреждений.–М.:просвещение, 2003.9-с. 9-11.
- Информатика. Задачник-практикум в 2 т. /Под ред. И.Г. Семакина, Е.К. Хеннера: Том 1. – Лаборатория Базовых Знаний, 1999 г. – 304 с.: ил.
- Практикум по информатике и информационным технологиям. Учебное пособие для общеобразовательных учреждений / Н.Д. Угринович, Л.Л. Босова, Н.И. Михайлова. – М.: Бином. Лаборатория Знаний, 2002. 400 с.: ил.
Алфавитный подход к оценке количества информации. Формула Хартли
Содержательный подход к оценке количества информации, который мы рассматривали ранее, измеряет ее количество, как уменьшение неопределенности наших знаний.
Однако любое техническое устройство не способно воспринимать непосредственно содержание информации, оно лишь понимает наличие или отсутствие электрических сигналов. Вследствие чего в вычислительной технике вынуждены использовать другой подход к оценке количества информации, который называется алфавитным.
Принцип алфавитного подхода к оценке количества информации
Алфавитный подход строится на принципе, утверждающем, что любое сообщение можно представить в виде кодов с помощью конечной последовательности символов, содержащейся в любом алфавите. Носители информации содержат любые последовательности символов, которые могут храниться, передаваться и обрабатываться как с помощью человека, так и с помощью технических устройств, в частности компьютера. Этот подход описал А.Н. Колмогоров, согласно которому, информативность, заключающаяся в последовательности символов, не может зависеть от содержания самого сообщения, а может определяться лишь минимальным количеством символов, необходимых для ее кодирования. Подобный подход к оценке количества информации носит объективный характер, так как не зависит от получателя, принимающего сообщения. Смысл же сообщений может учитываться только на этапе выбора алфавита кодирования либо не учитываться совсем.
Попробуй обратиться за помощью к преподавателям
В основу принципа этого подхода лег подсчет числа символов в сообщении, таким образом, важна только длина сообщения и совсем не учитывается его содержание. Однако на длину сообщения может влиять мощность алфавита используемого языка.
Самый простой способ разобраться в этом — рассмотреть пример любого текста, написанного на каком-нибудь языке. Для нас, конечно же, удобным будет текст на русском языке.
Мощность алфавита и информационная емкость. Формула Хартли
Все множество символов, из которых состоит язык, можно традиционно назвать алфавитом. Как правило, под алфавитом понимаются только буквы, но кроме них при написании текстов используются знаки препинания, цифры, скобки, пробелы, их тоже, в свою очередь, можно включить в алфавит.
Таким образом, алфавит — это множество символов, используемых при записи текста.
Мощность (размер) алфавита — это полное количество символов в алфавите.
Мощность алфавита обозначается буквой $N$.
Например:
мощность алфавита, состоящего из русских букв (кириллицы), равна $33$;
мощность алфавита, состоящего из латинских букв — $26$;
мощность алфавита текста набранного с клавиатуры компьютера равна $256$ (строчные и прописные латинские и русские буквы, цифры, знаки арифметических операций, скобки, знаки препинания и т.д.);
мощность двоичного алфавита равна $2$.
Задай вопрос специалистам и получи
ответ уже через 15 минут!
При алфавитном подходе считают, что каждый символ текста несет в себе определенную информационную емкость, которая, в свою очередь, зависит от мощности алфавита.
Алфавит, с помощью которого записывается сообщение, состоит из $N$ знаков. В самом простом случае при длине кода сообщения, равной одному знаку, отправитель может послать одно из $N$ возможных сообщений, которое будет нести количество информации, равное $I$, согласно формуле:
где $N$ — количество знаков в алфавите знаковой системы,
$I$ — количество информации, которое несет каждый знак.
Данную формулу вывел Р. Хартли, который в $20$-е годы прошлого столетия заложил основы теории информации, в которой определялась мера количества информации при решении некоторых задач.
Хартли утверждал, что на количество информации, содержащейся в сообщении, может влиять фактор неожиданности, который, в свою очередь, зависит от вероятности получения сообщения. Если эта вероятность получения сообщения высокая, а неожиданность при этом низкая, то сообщение будет содержать мало полезной для человека информации.
Однако при создании своей формулы Р.Хартли полностью исключил фактор неожиданности. Формула Хартли работает только в том случае, когда появление символов равновероятно и они статистически независимы.
Например, с помощью приведенной формулы можно определить количество информации, которое несет знак в двоичной системе счисления:
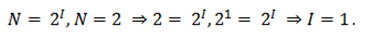
Информационная емкость знака двоичной системы составляет 1 бит.
Необходимо определить информационную емкость буквы русского алфавита (без учета буквы «ё»).
Решение:
Представим себе, что текст к нам поступает последовательно, по одному знаку, словно бумажная лента, выползающая из телеграфного аппарата. Предположим, что каждый символ, который появляется на ленте, с равной вероятностью может быть любым символом алфавита. В действительности это не совсем так, но для упрощения примем такое предположение.
В каждой очередной позиции текста может появиться любой из $N$ символов. Тогда, согласно известной нам формуле, каждый такой символ несет количество информации равное $I$ бит, которое можно определить из решения уравнения:
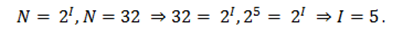
Информационная емкость буквы русского алфавита составляет $5$ бит информации.
Таким образом, формула определения $N$ связывает между собой количество возможных событий и количество информации, которое содержит в себе полученное сообщение. В рассматриваемой выше задаче $N$ — это количество знаков в русском алфавите, а $I$ — количество информации, которое несёт одна буква.
Сообщение состоит из последовательности знаков, каждый из которых несет определенное количество информации.
Количество информации в сообщении можно определить, используя формулу:
где $I_c$ — количество информации, содержащееся в сообщении;
$I$ — количество информации, которое несет один знак (информационная емкость);
$K$ — количество знаков в сообщении.
Рассмотрим пример решения задачи
Необходимо определить какое количество информации содержит слово «Привет», если считать, что алфавит состоит из $32$ букв (без учета буквы «ё»)?
Решение. Чтобы решить задачу, для начала определим количество знаков в сообщении и мощность используемого алфавита.
Количество знаков в сообщении: $K= 6$,
а мощность данного алфавита: $N = 32$.
Необходимо определить какое количество информации содержит слово «Привет».
Для этого необходимо умножить количество информации, которое несет один знак ($I$), на количество знаков в сообщении ($K$), т.е. воспользоваться формулой: $I_c = K \cdot I$.
Однако мы не сможем воспользоваться этой формулой, поскольку нам не известно какое количество информации несет один знак ($I$).
Для решения задачи воспользуемся формулой Хартли. Сообщение записано с помощью алфавита, мощность которого равна $32$, т.е. $N = 32$.
Решив уравнение, используя формулу $N = 2^I$, мы получили, что количество информации $I = 5$ бит. Зная количество информации, которое содержит в себе один знак нашего алфавита, и количество знаков в сообщении, можно определить, какое количество информации содержит наше сообщение.
Итак: $I_c = K \cdot I = 6 \cdot 5 = 30$ бит.
При измерении информации удобным является использование размера алфавита $N$, равного целой степени двойки. К примеру, если $N=16$, то это означает, что каждый символ несет $4$ бита информации, так как $2^4= 16$.
Единицы измерения информации
Ограничений максимального размера алфавита теоретически не существует. Однако существует алфавит, который можно назвать достаточным. Он используется при работе с компьютером. Мощность этого алфавита — $256$ символов. Он включает в себя практически все необходимые символы: латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания.
Поскольку $256 = 2^8$, то отсюда следует, что $1$ символ этого алфавита содержит $8$ бит информации. Эта величина лежит в основе использования вычислительной технике и носит название — байт.
Используя данный алфавит, который еще называется таблицей ASCII-кодов, можно легко подсчитать объем информации в тексте. В данном случае $1$ символ алфавита содержит в себе $1$ байт информации, поэтому необходимо просто определить количество символов, то число, которое получим в результате, и будет выражать информационный объем текста в байтах.
Допустим небольшая книга, распечатанная на принтере, содержит $50$ страниц, при этом на каждой странице расположено $50$ строк, в каждой строке — $60$ символов.
Проведем несложный расчет и получим, что страница содержит:
$50 \cdot 60 = 3000$ байт информации.
Объем же информации, содержащейся в книге:
$3000 \cdot 50 = 150 \ 000$ байт.
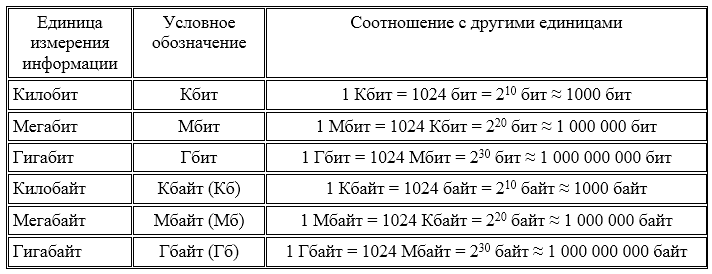
Любая система единиц измерения содержит основные единицы и производные от них.
При измерении больших объемов информации на практике широко используются следующие производные от байта единицы, которые приведены в таблице:
Так и не нашли ответ
на свой вопрос?
Просто напиши с чем тебе
нужна помощь
- http://xn----7sbbfb7a7aej.xn--p1ai/informatika_kabinet/inf_prozes/inf_prozes_05.html
- http://easyinformatics.ru/stati/opredelenie-kolichestva-informacii-v-soobshhenii
- http://biuv-school9tihvin.eduface.ru/folders/post/626981
- http://mylektsii.ru/7-65794.html
- http://spravochnick.ru/informatika/kodirovanie_informacii/alfavitnyy_podhod_k_ocenke_kolichestva_informacii_formula_hartli/