Алфавитный подход используется для измерения количества информации в тексте, представленном в виде последовательности символов некоторого алфавита. Такой подход не связан с содержанием текста. Количество информации в этом случае называется информационным объемом текста, который пропорционален размеру текста — количеству символов, составляющих текст. Иногда данный подход к измерению информации называют объемным подходом.
Каждый символ текста несет определенное количество информации. Его называют информационным весом символа. Поэтому информационный объем текста равен сумме информационных весов всех символов, составляющих текст.

Здесь предполагается, что текст — это последовательная цепочка пронумерованных символов. В формуле (1) i1 обозначает информационный вес первого символа текста, i2 — информационный вес второго символа текста и т.д.; K — размер текста, т.е. полное число символов в тексте.
Все множество различных символов, используемых для записи текстов, называется алфавитом. Размер алфавита — целое число, которое называется мощностью алфавита. Следует иметь в виду, что в алфавит входят не только буквы определенного языка, но все другие символы, которые могут использоваться в тексте: цифры, знаки препинания, различные скобки, пробел и пр.
Определение информационных весов символов может происходить в двух приближениях:
1) в предположении равной вероятности (одинаковой частоты встречаемости) любого символа в тексте;
2) с учетом разной вероятности (разной частоты встречаемости) различных символов в тексте.
Приближение равной вероятности символов в тексте
Если допустить, что все символы алфавита в любом тексте появляются с одинаковой частотой, то информационный вес всех символов будет одинаковым. Пусть N — мощность алфавита. Тогда доля любого символа в тексте составляет 1/N-ю часть текста. По определению вероятности (см. “Измерение информации. Содержательный подход”  ) эта величина равна вероятности появления символа в каждой позиции текста:
) эта величина равна вероятности появления символа в каждой позиции текста:
Согласно формуле К.Шеннона (см. “Измерение информации. Содержательный подход” ), количество информации, которое несет символ, вычисляется следующим образом:
Следовательно, информационный вес символа (i) и мощность алфавита (N) связаны между собой по формуле Хартли (см. “Измерение информации. Содержательный подход” )
Зная информационный вес одного символа (i) и размер текста, выраженный количеством символов (K), можно вычислить информационный объем текста по формуле:
Эта формула есть частный вариант формулы (1), в случае, когда все символы имеют одинаковый информационный вес.

Из формулы (2) следует, что при N = 2 (двоичный алфавит) информационный вес одного символа равен 1 биту.
С позиции алфавитного подхода к измерению информации 1 бит — это информационный вес символа из двоичного алфавита.
Более крупной единицей измерения информации является байт.
1 байт — это информационный вес символа из алфавита мощностью 256.
Поскольку 256 = 2 8 , то из формулы Хартли следует связь между битом и байтом:
Отсюда: i = 8 бит = 1 байт
Для представления текстов, хранимых и обрабатываемых в компьютере, чаще всего используется алфавит мощностью 256 символов. Следовательно,
1 символ такого текста “весит” 1 байт.
Помимо бита и байта, для измерения информации применяются и более крупные единицы:
1 Кб (килобайт) = 2 10 байт = 1024 байта,
1 Мб (мегабайт) = 2 10 Кб = 1024 Кб,
1 Гб (гигабайт) = 2 10 Мб = 1024 Мб.
Приближение разной вероятности встречаемости символов в тексте
В этом приближении учитывается, что в реальном тексте разные символы встречаются с разной частотой. Отсюда следует, что вероятности появления разных символов в определенной позиции текста различны и, следовательно, различаются их информационные веса.
Статистический анализ русских текстов показывает, что частота появления буквы “о” составляет 0,09. Это значит, что на каждые 100 символов буква “о” в среднем встречается 9 раз. Это же число обозначает вероятность появления буквы “о” в определенной позиции текста: po = 0,09. Отсюда следует, что информационный вес буквы “о” в русском тексте равен:

Самой редкой в текстах буквой является буква “ф”. Ее частота равна 0,002. Отсюда:

Отсюда следует качественный вывод: информационный вес редких букв больше, чем вес часто встречающихся букв.
Как же вычислить информационный объем текста с учетом разных информационных весов символов алфавита? Делается это по следующей формуле:

Здесь N — размер (мощность) алфавита; nj — число повторений символа номер j в тексте; ij — информационный вес символа номер j.
Методические рекомендации
Алфавитный подход в курсе информатики основой школы
В курсе информатики в основной школе знакомство учащихся с алфавитным подходом к измерению информации чаще всего происходит в контексте компьютерного представления информации. Основное утверждение звучит так:
Количество информации измеряется размером двоичного кода, с помощью которого эта информация представлена
Поскольку любые виды информации представляются в компьютерной памяти в форме двоичного кода, то это определение универсально. Оно справедливо для символьной, числовой, графической и звуковой информации.

Один знак (разряд) двоичного кода несет 1 бит информации.
При объяснении способа измерения информационного объема текста в базовом курсе информатики данный вопрос раскрывается через следующую последовательность понятий: алфавит — размер двоичного кода символа — информационный объем текста.
Логика рассуждений разворачивается от частных примеров к получению общего правила. Пусть в алфавите некоторого языка имеется всего 4 символа. Обозначим их: ,
,  ,
,  ,
,  . Эти символы можно закодировать с помощью четырех двухразрядных двоичных кодов: — 00, — 01, — 10, — 11. Здесь использованы все варианты размещений из двух символов по два, число которых равно 2 2 = 4. Отсюда делается вывод: информационный вес символа из 4-символьного алфавита равен двум битам.
. Эти символы можно закодировать с помощью четырех двухразрядных двоичных кодов: — 00, — 01, — 10, — 11. Здесь использованы все варианты размещений из двух символов по два, число которых равно 2 2 = 4. Отсюда делается вывод: информационный вес символа из 4-символьного алфавита равен двум битам.
Следующий частный случай — 8-символьный алфавит, каждый символ которого можно закодировать 3-разрядным двоичным кодом, поскольку число размещений из двух знаков группами по 3 равно 2 3 = 8. Следовательно, информационный вес символа из 8-символьного алфавита равен 3 битам. И т.д.
Обобщая частные примеры, получаем общее правило: с помощью b-разрядного двоичного кода можно закодировать алфавит, состоящий из N = 2 b — символов.
Пример 1. Для записи текста используются только строчные буквы русского алфавита и “пробел” для разделения слов. Какой информационный объем имеет текст, состоящий из 2000 символов (одна печатная страница)?
Решение. В русском алфавите 33 буквы. Сократив его на две буквы (например, “ё” и “й”) и введя символ пробела, получаем очень удобное число символов — 32. Используя приближение равной вероятности символов, запишем формулу Хартли:
Отсюда: i = 5 бит — информационный вес каждого символа русского алфавита. Тогда информационный объем всего текста равен:
I = 2000 · 5 = 10 000 бит
Пример 2. Вычислить информационный объем текста размером в 2000 символов, в записи которого использован алфавит компьютерного представления текстов мощностью 256.
Решение. В данном алфавите информационный вес каждого символа равен 1 байту (8 бит). Следовательно, информационный объем текста равен 2000 байт.
В практических заданиях по данной теме важно отрабатывать навыки учеников в пересчете количества информации в разные единицы: биты — байты — килобайты — мегабайты — гигабайты. Если пересчитать информационный объем текста из примера 2 в килобайты, то получим:
2000 байт = 2000/1024  1,9531 Кб
1,9531 Кб
Пример 3. Объем сообщения, содержащего 2048 символов, составил 1/512 часть мегабайта. Каков размер алфавита, с помощью которого записано сообщение?
Решение. Переведем информационный объем сообщения из мегабайтов в биты. Для этого данную величину умножим дважды на 1024 (получим байты) и один раз — на 8:
I = 1/512 · 1024 · 1024 · 8 = 16 384 бита.
Поскольку такой объем информации несут 1024 символа (К), то на один символ приходится:
Отсюда следует, что размер (мощность) использованного алфавита равен 2 16 = 65 536 символов.
Объемный подход в курсе информатики в старших классах
Изучая информатику в 10–11-х классах на базовом общеобразовательном уровне, можно оставить знания учащихся об объемном подходе к измерению информации на том же уровне, что описан выше, т.е. в контексте объема двоичного компьютерного кода.
При изучении информатики на профильном уровне объемный подход следует рассматривать с более общих математических позиций, с использованием представлений о частотности символов в тексте, о вероятностях и связи вероятностей с информационными весами символов.
Знание этих вопросов оказывается важным для более глубокого понимания различия в использовании равномерного и неравномерного двоичного кодирования (см. “Кодирование информации” ), для понимания некоторых приемов сжатия данных (см. “Сжатие данных” ) и алгоритмов криптографии (см. “Криптография” ).
Пример 4. В алфавите племени МУМУ всего 4 буквы (А, У, М, К), один знак препинания (точка) и для разделения слов используется пробел. Подсчитали, что в популярном романе “Мумука” содержится всего 10 000 знаков, из них: букв А — 4000, букв У — 1000, букв М — 2000, букв К — 1500, точек — 500, пробелов — 1000. Какой объем информации содержит книга?
Решение. Поскольку объем книги достаточно большой, то можно допустить, что вычисленная по ней частота встречаемости в тексте каждого из символов алфавита характерна для любого текста на языке МУМУ. Подсчитаем частоту встречаемости каждого символа во всем тексте книги (т.е. вероятность) и информационные веса символов


Общий объем информации в книге вычислим как сумму произведений информационного веса каждого символа на число повторений этого символа в книге:
Содержательный подход к измерению информации рассматривает информацию с точки зрения человека, как уменьшение неопределенности наших знаний.
Однако любое техническое устройство не воспринимает содержание информации.Поэтому в вычислительной технике используется другой подход к определению количества информации. Он называется алфавитным подходом.
При алфавитном подходе к определению количества информации отвлекаются от содержания информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Проще всего разобраться в этом на примере текста, написанного на каком-нибудь языке. Для нас удобнее, чтобы это был русский язык.
Все множество используемых в языке символов будем традиционно называть алфавитом. Обычно под алфавитом понимают только буквы, но поскольку в тексте могут встречаться знаки препинания, цифры, скобки, то мы их тоже включим в алфавит. В алфавит также следует включить и пробел, т.е. пропуск между словами.
Алфавит — множество символов, используемых при записи текста.
Мощность (размер) алфавита — полное количество символов в алфавите.
Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54.
Представьте себе, что текст к вам поступает последовательно, по одному знаку, словно бумажная ленточка, выползающая из телеграфного аппарата. Предположим, что каждый появляющийся на ленте символ с одинаковой вероятностью может быть любым символом алфавита. В действительности это не совсем так, но для упрощения примем такое предположение. В каждой очередной позиции текста может появиться любой из N символов. Тогда, согласно известной нам формуле N = 2 I (см. содержательный подход) каждый такой символ несет I бит информации, которое можно определить из решения уравнения: 2 I = 54. Получаем: I = 5.755 бит — такое количество информации несет один символ в русском тексте.
Чтобы найти количество информации во всем тексте, нужно посчитать число символов в нем и умножить на I.
Посчитаем количество информации на одной странице книги. Пусть страница содержит 50 строк. В каждой строке — 60 символов. Значит, на странице умещается 50×60=3000 знаков. Тогда объем информации будет равен: 5,755 х 3000 = 17265 бит.
При алфавитном подходе к измерению информации количество информации зависит не от содержания, а от размера текста и мощности алфавита.
Таким образом, алфавитный подход к измерению информации можно изобразить в виде таблицы:
При использовании двоичной системы (алфавит состоит из двух знаков: 0 и 1) каждый двоичный знак несет 1 бит информации.
Применение алфавитного подхода удобно, прежде всего, при использовании технических средств работы с информацией. В этом случае теряют смысл понятия «новые — старые», «понятные — непонятные» сведения.
Алфавитный подход является объективным способом измерения информации в отличие от субъективного содержательного подхода.
Удобнее всего измерять информацию, когда размер алфавита N равен целой степени двойки. Например, если N=16, то каждый символ несет 4 бита информации потому, что 2 4 = 16. А если N =32, то один символ «весит» 5 бит.
Ограничения на максимальный размер алфавита теоретически не существует. Однако есть алфавит, который можно назвать достаточным. С ним мы встречались при рассмотрении темы «Кодирование текствовой информации». Это алфавит мощностью 256 символов. В алфавит такого размера можно поместить все практически необходимые символы: латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания.
Поскольку 256 = 2 8 , то один символ этого алфавита «весит» 8 бит. Причем 8 бит информации — это настолько характерная величина, что ей даже присвоили свое название — байт.
1 байт = 8 бит.
Для измерения больших объемов информации используются следующие единицы:
1 Кб (один килобайт) = 1024 байт = 2 10 байт
1 Мб (один мегабайт) = 1024 Кб= 2 10 Кбайт = 2 20 байт
1 Гб (один гигабайт) = 1024 Мб= 2 10 Mбайт = 2 30 байт
1Тбайт (один терабайт)= 2 10 Гбайт = 1024Гбайт = 2 40 байт
1Пбайт(один петабайт)= 2 10 Тбайт = 1024Тбайт = 2 50 байт
1Эбайт(один экзабайт)= 2 10 Пбайт = 1024Пбайт = 2 60 байт
1Збайт(один зетабайт)= 2 10 Эбайт = 1024Эбайт = 2 70 байт
1Йбайт(один йотабайт)= 2 10 Збайт = 1024Збайт = 2 80 байт .
Алфавитный подход к измерению информации
Содержательный (вероятностный) подход к измерению информации определяет количество информации, которое содержится в сообщениях, уменьшающих неопределенность наших знаний, т. е. мы рассматривали информацию со своей точки зрения — с позиции человека.Для нас количество информации зависит от ее содержания, понятности и новизны. Однако любое техническое устройство не воспринимает содержание информации. Здесь не работают «неопределенность знаний» и «вероятность информации». Поэтому в вычислительной технике используется другой подход к измерению информации.
Вокруг нас везде и всюду происходят информационные обмены. Информацией обмениваются между собой люди, животные, технические устройства, органы человека или животного и т.д. во всех этих случаях передача информации происходит в виде последовательностей различных сигналов. В вычислительной технике такие сигналы кодируют определенные смысловые символы, т.е. такие сигналы кодируют последовательности знаков, букв, цифр, кодов цвета точек и т.д. С этой точки зрения рассматривается другой подход к измерению информации — алфавитный.
У нас есть небольшой текст, написанный на русском языке. Он состоит из букв русского алфавита, цифр, знаков препинания. Для простоты будем считать, что символы в тексте присутствуют с одинаковой вероятностью.
Множество используемых в тексте символов называется алфавитом. В информатике под алфавитом понимают не только буквы, но и цифры, и знаки препинания, и другие специальные знаки. У алфавита есть размер (полное количество его символов), который называется мощностью алфавита.
Обозначим мощность алфавита через N. Тогда воспользуемся формулой для нахождения количества информации их вероятностного подхода: I = log2N.
Для расчета количества информации по этой формуле нам необходимо найти мощность алфавита N.
Пример 1
Найти объем информации, содержащейся в тексте из 3000 символов, написанном русскими буквами.
Решение:
1) Найдем мощность алфавита:
N = 33 русских прописных буквы + 33 русских строчных букв + 21 специальный знак = 87 символов. Подставим в формулу и рассчитаем количество информации:
2) I = Iog287 = 6,4 бита.
Такое количество информации — информационный объем — несет один символ в русском тексте. Теперь, чтобы найти количество информации во всем тесте, нужно найти общее количество символов в нем и умножить на информационный объем одного символа. Значит:
3) 6,4·3000= 19140 бит.
Теперь переведем этот текст на немецкий язык. Причем так, чтобы в тексте осталось 3000 символов. Содержание текста при этом осталось точно такое же. Поэтому с точки зрения вероятностного подхода количество информации также не изменится, т.е. новых понятных знаний не прибавилось и не убавилось.
Пример 2
Найти количество информации, содержащейся в немецком тексте с таким же количеством символов.
Решение:Найдем мощность немецкого алфавита:
1) N = 26 немецких прописных буквы + 26 немецких строчных букв + 21
специальный знак = 73 символа.
Найдем информационный объем одного символа:
2) I = 1og273 = 6,1бит.
Найдем объем всего текста.
3) 6,1·3000 =18300 бит.
Сравнивая объемы информации русского текста и немецкого, мы видим, что на немецком языке информации меньше, чем на русском. Но ведь содержание не изменилось. Следовательно, при алфавитном подходе к измерению информации ее количество не зависит от содержания, а зависит от мощности алфавита и количества символов в тексте. С точки зрения алфавитного подхода, в толстой книге информации больше, чем в тонкой. При этом содержание книги не учитывается.
Правило для измерения информации с точки зрения алфавитного подхода.
1. Найти мощность алфавита — N.
2. Найти информационный объем одного символа — I = log2N.
3. Найти количество символов в сообщении — К.
4. Найти информационный объем всего сообщения — К·I.
Пример 3
Найти объем текста, записанного на языке, алфавит которого содержит 128 символов и 2000 символов в сообщении.
Дано: К = 2000, N= 128.
Решение:
1) I = log2N = log2128 = 7 бит — объем одного символа.
1) Iт = I·K = 7·2000 = 14000 бит — объем сообщения.
Ответ:14000 бит.
Обмен информацией происходит с разной скоростью. Если говорить о людях,то темп речи очень важен для взаимопонимания. Некоторые люди разваривают очень медленно, другие — наоборот быстро . Скорость чтения также у людей бывает разная.
Скорость передачи информации называется скоростью информационного потока и выражается в битах в секунду (бит/с), байтов в секунду (байт/с), Кбайтов в секунду (Кб/с) и т.д. Скорость чтения и скорость речи можно вычислить. Скорость информационного потока в случае, когда он происходит между техническими устройствами, намного выше, чем между людьми. Прием и передачи информации в этом случае происходит по каналам связи. К основным характеристикам каналов связи относятся:
— максимальная скорость передачи информации по каналу связи называется пропускной способностью канала;
Сегодня предпочтение отдается высокоскоростному оптоволокну. Информация по таким каналам связи передается в виде светового сигнала, посылаемого лазерным излучателем.
6. Алфавитный подход к измерению информации.
А теперь познакомимся с другим способом измерения информации. Этот способ не связывает количество информации с содержанием сообщения, и называется он алфавитным подходом.
При алфавитном подходе к определению количества информации отвлекаются от содержания информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Проще всего разобраться в этом на примере текста, написанного на каком-нибудь языке. Для нас удобнее, чтобы это был русский язык.
Все множество используемых в языке символов будем традиционно называть алфавитом. Обычно под алфавитом понимают только буквы, но поскольку в тексте могут встречаться знаки препинания, цифры, скобки, то мы их тоже включим в алфавит. В алфавит также следует включить и пробел, т.е. пропуск между словами.
Полное количество символов алфавита принято называть мощностью алфавита. Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54.
Представьте себе, что текст к вам поступает последовательно, по одному знаку, словно бумажная ленточка, выползающая из телеграфного аппарата. Предположим, что каждый появляющийся на ленте символ с одинаковой вероятностью может быть любым символом алфавита. В действительности это не совсем так, но для упрощения примем такое предположение.
В каждой очередной позиции текста может появиться любой из N символов. Тогда, согласно известной нам формуле, каждый такой символ несет I бит информации, которое можно определить из решения уравнения: 2I = 54. Получаем: I = 5.755 бит.
Вот сколько информации несет один символ в русском тексте! А теперь для того, чтобы найти количество информации во всем тексте, нужно посчитать число символов в нем и умножить на I.
Посчитаем количество информации на одной странице книги. Пусть страница содержит 50 строк. В каждой строке — 60 символов. Значит, на странице умещается 50×60=3000 знаков. Тогда объем информации будет равен: 5,755 х 3000 = 17265 бит.
При алфавитном подходе к измерению информации количество информации зависит не от содержания, а от размера текста и мощности алфавита.
При использовании двоичной системы (алфавит состоит из двух знаков: 0 и 1) каждый двоичный знак несет 1 бит информации. Интересно, что сама единица измерения информации «бит» получила свое название от английского сочетания «binary digit» — «двоичная цифра».
Применение алфавитного подхода удобно прежде всего при использовании технических средств работы с информацией. В этом случае теряют смысл понятия «новые — старые», «понятные — непонятные» сведения. Алфавитный подход является объективным способом измерения информации в отличие от субъективного содержательного подхода.
Удобнее всего измерять информацию, когда размер алфавита N равен целой степени двойки. Например, если N=16, то каждый символ несет 4 бита информации потому, что 24 = 16. А если N =32, то один символ «весит» 5 бит.
Ограничения на максимальный размер алфавита теоретически не существует. Однако есть алфавит, который можно назвать достаточным. С ним мы скоро встретимся при работе с компьютером. Это алфавит мощностью 256 символов. В алфавит такого размера можно поместить все практически необходимые символы: латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания.
Поскольку 256 = 28, то один символ этого алфавита «весит» 8 бит. Причем 8 бит информации — это настолько характерная величина, что ей даже присвоили свое название — байт.
Сегодня очень многие люди для подготовки писем, документов, статей, книг и пр. используют компьютерные текстовые редакторы. Компьютерные редакторы, в основном, работают с алфавитом размером 256 символов.
В этом случае легко подсчитать объем информации в тексте. Если 1 символ алфавита несет 1 байт информации, то надо просто сосчитать количество символов; полученное число даст информационный объем текста в байтах.
Пусть небольшая книжка, сделанная с помощью компьютера, содержит 150 страниц; на каждой странице — 40 строк, в каждой строке — 60 символов. Значит страница содержит 40×60=2400 байт информации. Объем всей информации в книге: 2400 х 150 = 360 000 байт.
В любой системе единиц измерения существуют основные единицы и производные от них.
Для измерения больших объемов информации используются следующие производные от байта единицы:
1 килобайт = 1Кб = 210 байт = 1024 байта.
1 мегабайт = 1Мб = 210 Кб = 1024 Кб.
1 гигабайт = 1Гб = 210 Мб = 1024 Мб.
Прием-передача информации могут происходить с разной скоростью. Количество информации, передаваемое за единицу времени, есть скорость передачи информации или скорость информационного потока.
Очевидно, эта скорость выражается в таких единицах, как бит в секунду (бит/с), байт в секунду (байт/с), килобайт в секунду (Кбайт/с) и т.д.
Алфавитный подход к определению количества информации
Цели урока:
1) Обучающая: рассмотреть алфавитный подход к измерению количества информации, научиться вычислять количество информации с точки зрения алфавитного подхода.
2) Развивающая: развитие у учащихся самостоятельности и познавательной активности.
3) Воспитывающая: воспитывать дисциплинированность, аккуратность, собранность.
Литература:
1) Угринович Н. Д. «Информатика 8 класс»,
2) Заславская О. Ю., Левченко И. В. «Информатика: весь курс».
1) Угринович Н. Д. «Информатика 8 класс».
Тип урока: ознакомление с новым материалом
План урока:
1. Организационный этап.
2. Актуализация знаний.
3. Подготовка учащихся к усвоению нового материала.
4. Этап получения новых знаний.
5. Этап обобщения и закрепления нового материала.
7. Заключительный этап.
Ход урока
1. Организационный этап.
Здравствуйте. Прежде чем мы приступим к уроку, хотелось бы, чтобы каждый из вас настроился на рабочий лад.
2. Актуализация знаний.
1) В чём заключается содержательный подход к измерению информации? (Количество информации — мера уменьшения неопределённости знаний при получении информационных сообщений.)
2) Какую минимальную единицу информации используют для измерения количества информации? (Бит)
3) Какую формулу используют для определения количества информации? (Формулу Хартли)
4) Производится бросание симметричной четырехгранной пирамидки. Какое количество информации мы получаем в зрительном сообщении о ее падении на одну из граней? (2 бита)
6) Из непрозрачного мешочка вынимают шарики с номерами и известно, что информационное сообщение о номере шарика несет 5 битов информации. Определите количество шариков в мешочке. (35)
3. Этап получения новых знаний.
Скачать видеоурок «Алфавитный подход к определению количества информации»
Содержательный подход к измерению информации рассматривает информацию с точки зрения человека, как уменьшение неопределенности наших знаний.
Однако любое техническое устройство не воспринимает содержание информации. Поэтому в вычислительной технике используется другой подход к определению количества информации. Он называется алфавитным подходом.
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Проще всего разобраться в этом на примере текста, написанного на каком-нибудь языке. Для нас удобнее, чтобы это был русский язык.
Все множество используемых в языке символов будем традиционно называть алфавитом. Обычно под алфавитом понимают только буквы, но поскольку в тексте могут встречаться знаки препинания, цифры, скобки, то мы их тоже включим в алфавит. В алфавит также следует включить и пробел, пропуск между словами.
Алфавит — это множество символов, используемых при записи текста.
Мощность (размер) алфавита — это полное количество символов в алфавите.
Мощность алфавита обозначается буквой N.
· мощность алфавита из русских букв равна 33;
· мощность алфавита из латинских букв — 26;
· мощность алфавита текста набранного с клавиатуры равна 256 (строчные и прописные латинские и русские буквы, цифры, знаки арифметических операций, скобки, знаки препинания );
· мощность двоичного алфавита равна 2.
При алфавитном подходе считается, что каждый символ текста имеет информационную емкость. Информационная емкость знака зависит от мощности алфавита.
Алфавит, с помощью которого записано сообщение состоит из N знаков. В простейшем случае, когда длина кода сообщения составляет один знак, отправитель может послать одно из N возможных сообщений, которое будет нести количество информации I.
Тогда в формуле
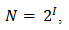
N — количество знаков в алфавите знаковой системы, I — количество информации, которое несет каждый знак.
Например, из формулы можно определить количество информации, которое несет знак в двоичной знаковой системе
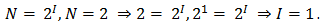
Информационная емкость знака двоичной знаковой системы составляет 1 бит.
Задача 1. Определите, какое количество информации несет буква русского алфавита (без буквы ё).
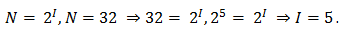
Буква русского алфавита несет 5 битов информации.
Формула 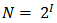 связывает между собой количество возможных событий и количество информации, которое несёт полученное сообщение. В рассматриваемой ситуации N — это количество знаков в алфавите, знаковой системы, а I — количество информации, которое несёт один знак.
связывает между собой количество возможных событий и количество информации, которое несёт полученное сообщение. В рассматриваемой ситуации N — это количество знаков в алфавите, знаковой системы, а I — количество информации, которое несёт один знак.
Сообщение состоит из последовательности знаков, каждый из которых несет определенное количество информации.
Количество информации в сообщении можно посчитать, умножив количество информации, которое несет один знак на количество знаков в сообщении.
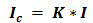
где 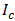 — количество информации в сообщении
— количество информации в сообщении
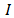 — количество информации, которое несет один знак
— количество информации, которое несет один знак
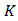 — количество знаков в сообщении
— количество знаков в сообщении
Давайте решим с вами задачу.
Задача 2. Какое количество информации содержит слово «ПРИВЕТ», если считать, что алфавит состоит из 32 букв?
Решение. Что нам требуется найти в данной задаче? Нам нужно найти какое количество информации содержит слово «ПРИВЕТ».
Что нам для этого дано?
Дано: количество знаков в сообщение и мощность алфавита.
Количество знаков в сообщении равно 6, а мощность данного алфавита равна 32.
Что нам нужно найти? Нам нужно найти какое количество информации содержит слово «ПРИВЕТ».
Посмотрим на наше сообщение, оно содержит несколько знаков, значит для того чтобы найти количество информации нашего сообщения, нам нужно умножив количество информации, которое несет один знак, на количество знаков в сообщении, воспользоваться формулой «и» суммарное равно «и» умножить на «к».
Но мы еще не можем воспользоваться формулой, т.к. не знаем какое количество информации несет один знак. Для этого воспользуемся формулой Хартли. Сообщение записано с помощью алфавита, мощность которого равна 32, N равно 32. Мы получили уравнение. Решив это уравнение, мы получили, что количество информации, которое несет один знак нашего алфавита, равно 5 бит. Зная количество информации, которое несет один знак нашего алфавита, и количество знаков в сообщении, мы можем найти какое количество информации содержит наше сообщение.
Итак, наше сообщение содержит 30 бит.
4. Этап обобщения и закрепления нового материала.
1) Какое количество информации содержит слово «ИНФОРМАТИКА», если считать, что алфавит состоит из 32 букв? (55 битов)
2) Определить количество информации, содержащееся в слове из 10 символов, если известно, что мощность алфавита равна 32 символам. (50 бит)
3) Сколько бит информации содержится в сообщении, состоящем из 5 символов, при использовании алфавита, состоящего из 64 символов. (6 битов)
4) Определить информативность сообщения «А + В = С», если для описания математических формул необходимо воспользоваться 64-символьным алфавитом. (30 бит)
5) Для представления числовых данных используют 16-ричный алфавит, включающий знаки математических действий. Сколько битов информации содержит выражение «32 * 5 = 160»? (32 бита)
6) Практическая работа № 2. «Тренировка ввода текстовой и числовой информации с помощью клавиатурного тренажера»
5. Рефлексия.
Алфавитный подход к определению количества информации
При алфавитном подходе к определению количества информации отвлекаются от содержания информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Информационная емкость знака. Представим себе, что необходимо передать информационное сообщение по каналу передачи информации от отправителя к получателю. Пусть сообщение кодируется с помощью знаковой системы, алфавит которой состоит из N знаков . В простейшем случае, когда длина кода сообщения составляет один знак, отправитель может послать одно из N возможных сообщений «1», «2», . «N», которое будет нести количество информации I (рис. 1.5).
| Рис. 1.5. Передача информации |
Формула (1.1) связывает между собой количество возможных информационных сообщений N и количество информации I, которое несет полученное сообщение. Тогда в рассматриваемой ситуации N — это количество знаков в алфавите знаковой системы, а I — количество информации, которое несет каждый знак:
С помощью этой формулы можно, например, определить количество информации, которое несет знак в двоичной знаковой системе:
N = 2 => 2 = 2 I => 2 1 = 2 I => I=1 бит.
Таким образом, в двоичной знаковой системе знак несет 1 бит информации. Интересно, что сама единица измерения количества информации «бит» (bit) получила свое название ОТ английского словосочетания «Binary digiT» — «двоичная цифра».
Информационная емкость знака двоичной знаковой системы составляет 1 бит.
Чем большее количество знаков содержит алфавит знаковой системы, тем большее количество информации несет один знак. В качестве примера определим количество информации, которое несет буква русского алфавита. В русский алфавит входят 33 буквы, однако на практике часто для передачи сообщений используются только 32 буквы (исключается буква «ё»).
С помощью формулы (1.1) определим количество информации, которое несет буква русского алфавита:
N = 32 => 32 = 2 I => 2 5 = 2 I => I=5 битов.
Таким образом, буква русского алфавита несет 5 битов информации (при алфавитном подходе к измерению количества информации).
Количество информации, которое несет знак, зависит от вероятности его получения. Если получатель заранее точно знает, какой знак придет, то полученное количество информации будет равно 0. Наоборот, чем менее вероятно получение знака, тем больше его информационная емкость.
В русской письменной речи частота использования букв в тексте различна, так в среднем на 1000 знаков осмысленного текста приходится 200 букв «а» и в сто раз меньшее количество буквы «ф» (всего 2). Таким образом, с точки зрения теории информации, информационная емкость знаков русского алфавита различна (у буквы «а» она наименьшая, а у буквы «ф» — наибольшая).
Количество информации в сообщении. Сообщение состоит из последовательности знаков, каждый из которых несет определенное количество информации.
Если знаки несут одинаковое количество информации, то количество информации Ic в сообщении можно подсчитать, умножив количество информации Iз, которое несет один знак, на длину кода (количество знаков в сообщении) К:
Так, каждая цифра двоичного компьютерного кода несет информацию в 1 бит. Следовательно, две цифры несут информацию в 2 бита, три цифры — в 3 бита и т. д. Количество информации в битах равно количеству цифр двоичного компьютерного кода (табл. 1.1).
Таблица 1.1. Количество информации, которое несет двоич ный компьютерный код
| Двоичный компьютерный код | |||||
| Количество информации | 1 бит | 1 бит | 1 бит | 1 бит | 1 бит |
Понятие ценности информации, вводимое в настоящей главе, связывает шенноновскую теорию информации с теорией стастисти-ческих решений. В последней теории основным является понятие средних потерь или риска, которое характеризирует качество принимаемых решений. Ценность информации специализируется как та максимальная польза, которую данное количество информации способно принести в деле уменьшения средних потерь. Такое определение ценности информации оказывается связанным с формулировкой и решением определенных условных вариационных задач. [1]
Ввести понятие ценности информации можно тремя родственными способами, выбирая за основу хартлиевское, больцмановское или шенноновское количество информации. При выборе шеннонов-ского количества информации нужно решать третью вариационную задачу. Между указанными определениями существует известная связь, и одно понятие может служить удобной заменой другого. Все эти понятия характеризуют определенный объект — бейесов-скую систему, который наряду с каналом является важнейшим объектом исследования теории информации. [2]
Вводится понятие ценности информации и демонстрируются различные варианты понятия макси-мина ( наилучшего гарантированного результата) в зависимости от информированности об обстановке операций. Излагаются необходимые условия максимина и примеры его определения для ряда моделей операций, имеющих не только учебный характер. [3]
Таким образом, понятие ценности информации, введенное в предыдущем разделе, шире понятия сложности и, в сущности, включает сложность. Пользуясь понятием ценности, можно преодолеть трудность, связанную с тем, что в эволюции может происходить не усложнение, но упрощение. [4]
Важно отметить, что понятие ценности информации, используемой при контроле функционирования АС, является многогранным и в значительной мере субъективным. Многогранность понятия определяется, с одной стороны, степенью соответствия получаемой информации конкретной задаче контроля, а с другой — возможностью, целесообразностью и своевременностью ее получения. Так, например, интуитивно ясно, что состояние сложной энергетической системы определяется уровнем вырабатываемой или аккумулируемой энергии. [5]
Мы видим, что понятие сложности сходно с понятием ценности информации, рассмотренным в предыдущем параграфе. [6]
Для того чтобы правильно ставить такого рода вопросы, необходимо ввести понятие ценности информации, и это в дальнейшем будет сделано в полном соответствии с проводимыми здесь идеями о сравнении эффективности стратегий вообще. [7]
Таким образом, последнее условие ( хотя оно часто и не принимается во внимание) имеет по существу главное определяющее значение в формулировке понятия ценности информации. [8]
Уменьшение избыточной информации может быть выполнено на основании анализа ценности информации для управления. Как известно, понятие ценности информации не вытекает из самой теории информации, основанной на статистической трактовке вопросов. [9]
Здесь не рассматривается генерация информации и ее инструктирующее значение, определяющее ту или иную биологическую функцию носителя информации. При исследовании развивающейся и эволюционирующей системы необходимо ввести понятие ценности информации для реализации конкретного процесса, эквивалентное ее программирующему, инструктирующему, значению. Ценность информации выражает ее содержание, тогда как количество информации не имеет отношения к ее содержанию. Содержание можно оценить лишь применительно к определенным физическим процессам. [10]
В общем случае работа динамической биологической системы означает реализацию инструктивного, программирующего значения информации, содержащейся в конечном счете в биологических макромолекулах нуклеиновых кислот и белков. Модельное описание такой системы действительно требует понятия ценности информации как инструктирующего фактора. Такое понятие, вообще говоря, не может быть универсальным. Оно должно выражаться в строгих физико-математических терминах применительно к конкретным биологическим процессам. Эйген вводит понятие селективной ценности, характеризующей кинетику матричного синтеза биологических макромолекул. Изложение этой теории и некоторых других вопросов, связанных с понятием ценности информации в биологии, дано в гл
Показатели качества информации
Показатели качества информации
Информация в системе управления является и предметом труда, и продуктом труда, поэтому от ее качества существенно зависят эффективность и качество функционирования системы.
Качество информации можно определить как совокупность свойств, обусловливающих возможность ее использования для удовлетворения определенных в соответствии с ее назначением потребностей.
Рекомендуется выделять следующие основные виды показателей качества промышленной продукции:
□ показатели назначения, характеризующие полезный эффект от использования продукции по назначению и обусловливающие область ее применения;
U показатели надежности и долговечности, характеризующие одноименные е.нойства изделий в конкретных условиях их использования;
L) показатели технологичности, обусловливающие высокую производительность труда при изготовлении и ремонте продукции;
U эргономические показатели, учитывающие комплекс физиологических, психологических, антропометрических параметров человека;
L) эстетические показатели, характеризующие такие свойства продукции, как иi>iразительность, гармоничность, соответствие среде, стилю и т. п.;
U показатели стандартизации и унификации продукции;
U патентно-правовые показатели, характеризующие патентную чистоту изделий и степень его патентной защиты в стране;
U показатели экономические, отражающие затраты на разработку, изготовление и эксплуатацию или потребление продукции, а также экономическую эффективность эксплуатации.
Однако информация — весьма своеобразная, не материальная продукция, поэтому применить к ней в полном объеме данные рекомендации невозможно. Анализируя возможность использования названных видов показателей качества, можно сформулировать систему основных показателей качества экономической информации.
Возможность и эффективность использования информации для управления обусловливается такими ее потребительскими показателями качества, как репрезентативность, содержательность, достаточность, доступность, своевременность, устойчивость, точность, достоверность, актуальность и ценность.
Репрезентативность — правильность, качественная адекватность отражения заданных свойств объекта. Репрезентативность информации зависит от правильности ее отбора и формирования. Важнейшее значение при этом приобретают: верность концепции, на базе которой сформулировано исходное понятие, отображаемое показателем; обоснованность отбора существенных признаков и связей отображаемого явления; правильность методики измерения и алгоритма формирования экономического показателя. Нарушение репрезентативности информации приводит нередко к существенным ее погрешностям, называемым чаще всего алгоритмическими.
Содержательность информации — это ее удельная семантическая емкость, равная отношению количества семантической информации в сообщении к объему данных, его отображающих, то есть S = IC/VA. С увеличением содержательности информации растет семантическая пропускная способность информационной системы, так как для передачи одних и тех же сведений требуется преобразовы-иать меньший объем данных. Наряду с содержательностью можно использовать и показатель информативности, характеризующийся отношением количества синтаксической информации (по Шеннону) к объему данных — Y = I/V&. Поскольку в правильно организованных системах управления количество семантической информации пропорционально, а часто и равно количеству синтаксической информации в сообщении, то значение S часто может характеризоваться значением Y.
Доступность информации для восприятия при принятии управленческого решения обеспечивается выполнением соответствующих процедур ее получения и преобразования. Так, назначением вычислительной системы является увеличение ценности информации путем согласования ее с тезаурусом пользователя, то есть преобразование ее к доступной и удобной для восприятия пользователем форме.
Актуальность информации — это свойство информации сохранять свою полезность (ценность) для управления во времени. Измеряется актуальность A(f) степенью сохранения начальной ценности информации Z(t0) в момент времени t ее использования:
где Z(t) — ценность информации в момент времени t
Актуальность зависит от статистических характеристик отображаемого объекта (от динамики изменения этих характеристик) и от интервала времени, прошедшего с момента возникновения данной информации.
Своевременность — это свойство информации, обеспечивающее возможность ее использования в заданный момент времени. Несвоевременная информация приводит к экономическим потерям и в сфере управления, и в сфере производства. Причиной, обусловливающей экономические потери от несвоевременности в сфере управления, является нарушение установленного режима решения функциональных задач, а иногда и их алгоритмов. Это приводит к увеличению стоимости решения задач вследствие снижения ритмичности, увеличения простоев и сверхурочных работ и т. п. в сфере материального производства. Потери от несвоевременности информации связаны со снижением качества управленческих решений, принятием решения на базе неполной информации или информации некачественной. Своевременной является такая информация, которая может быть учтена при выработке управленческого решения без нарушения регламента, поступающая в систему управления не позже назначенного момента времени.
Точность информации — это степень близости отображаемого информацией значения и истинного значения данного параметра. Для экономических показателей, отображаемых цифровым кодом, известны четыре классификационных понятия точности:
□ формальная точность, измеряемая значением единицы младшего разряда числа, которым показатель представлен;
□ реальная точность, определяемая значением единицы последнего разряда числа, верность которого гарантируется;
□ достижимая точность — максимальная точность, которую можно получить в данных конкретных условиях функционирования системы;
□ необходимая точность, определяемая функциональным назначением показателя и обеспечивающая правильность принимаемого управленческого решения.
Достоверность информации — свойство информации отражать реально существующие объекты с необходимой точностью. Измеряется достоверность информации доверительной вероятностью необходимой точности, то есть вероятностью того, что отображаемое информацией значение параметра отличается от истинного значения этого параметра в пределах необходимой точности. Наряду с понятием «достоверность информации», существует понятие «достоверность данных», то есть информации, рассматриваемой в синтаксическом аспекте. Под достоверностью данных понимается их безошибочность; измеряемая вероятностью появления ошибок в данных. Недостоверность данных может не повлиять на объем данных, а может даже и увеличить его, в отличие от недостоверности информации, всегда уменьшающей ее количество.
Устойчивость информации — свойство результатной информации реагировать на изменения исходных данных, сохраняя необходимую точность. Устойчивость информации, как и ее репрезентативность, обусловлена в первую очередь методической правильностью ее отбора и формирования.
Ценность экономической информации — комплексный показатель ее качества, ее мера на прагматическом уровне. Ценность экономической информации определяется эффективностью осуществляемого на ее основе экономического управления.
Успешное внедрение информационных технологий связано с возможностью их типизации. Конкретная информационная технология обладает комплексным составом компонентов, поэтому целесообразно определить ее структуру и состав.
Конкретная информационная технология определяется в результате компиляции и синтеза базовых технологических операций, специализированных технологий и средств реализации.
Технологический процесс — часть информационного процесса, содержащая действия (физические, механические и др.) по изменению состояния информации.
Информационная технология базируется на реализации информационных процессов, разнообразие которых требует выделения базовых, характерных для любой информационной технологии.
Базовый технологический процесс основан на использовании стандартных моделей и инструментальных средств и может быть использован в качестве составной части информационной технологии. К их числу можно отнести: операции извлечения, транспортировки, хранения, обработки и представления информации.
Среди базовых технологических процессов выделим:
представление и использование информации.
Процесс извлечения информации связан с переходом от реального представления предметной области к его описанию в формальном виде и в виде данных, которые отражают это представление.
В процессе транспортирования осуществляют передачу информации на расстояние для ускоренного обмена и организации быстрого доступа к ней, используя при этом различные способы преобразования.
Процесс обработки информации состоит в получении одних «информационных объектов» из других «информационных объектов», путем выполнения некоторых алгоритмов; он является одной из основных операций, выполняемых над информацией и главным средством увеличения ее объема и разнообразия.
Процесс хранения связан с необходимостью накопления и долговременного хранения данных, обеспечением их актуальности, целостности, безопасности, доступности.
Процесс представления и использования информации направлен на решение задачи доступа к информации в удобной для пользователя форме.
Базовые информационные технологии строятся на основе базовых технологических операций, но кроме этого включают ряд специфических моделей и инструментальных средств. Этот вид технологий ориентирован на решение определенного класса задач и используется в конкретных технологиях в виде отдельной компоненты. Среди них можно выделить:
технологии защиты информации;
технологии искусственного интеллекта.
Специфика конкретной предметной области находит отражение в специализированных информационных технологиях, например, организационное управление, управление технологическими процессами, автоматизированное проектирование, обучение и др. Среди них наиболее продвинутыми являются следующие информационные технологии:
организационного управления (корпоративные информационные технологии);
в промышленности и экономике;
Аналогом инструментальной базы (оборудование, станки, инструмент) являются средства реализации информационных технологий, которые можно разделить на методические, информационные, математические, алгоритмические, технические и программные.
CASE-технология (Computer Aided Software Engineering — Компьютерное Автоматизированное Проектирование Программного обеспечения) является своеобразной «технологической оснасткой», позволяющей осуществить автоматизированное проектирование информационных технологий.
Методические средства определяют требования при разработке, внедрении и эксплуатации информационных технологий, обеспечивая информационную, программную и техническую совместимость. Наиболее важными из них являются требования по стандартизации.
Информационные средства обеспечивают эффективное представление предметной области, к их числу относятся информационные модели, системы классификации и кодирования информации (общероссийские, отраслевые) и др.
Математические средства включают в себя модели решения функциональных задач и модели организации информационных процессов, обеспечивающие эффективное принятие решения. Математические средства автоматически переходят в алгоритмические, обеспечивающие их реализацию.
Технические и программные средства задают уровень реализации информационных технологий как при их создании, так и при их реализации.
Таким образом, конкретная информационная технология определяется в результате компиляции и синтеза базовых технологических операций, отраслевых технологий и средств реализации.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Сдача сессии и защита диплома — страшная бессонница, которая потом кажется страшным сном. 7964 —  | 6578 —
| 6578 —  или читать все.
или читать все.
193.124.117.139 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
- http://dpk-info.ucoz.ru/publ/13-1-0-21
- http://megaobuchalka.ru/12/1969.html
- http://studfiles.net/preview/4349019/page:5/
- http://videouroki.net/blog/alfavitnyy-podkhod-k-opredeleniyu-kolichestva-informatsii.html
- http://studopedia.ru/9_137667_alfavitniy-podhod-k-opredeleniyu-kolichestva-informatsii.html