Каждая знаковая система строится на основе определенного алфавита (набора знаков ) и правил выполнения операций над знаками.
Человек широко использует для представления информации знаковые системы, которые называются языками. Естественные языки начали формироваться еще в древнейшие времена в целях обеспечения обмена информацией между людьми. В настоящее время существуют сотни естественных языков (русский, английский, китайский и др.).
Формальные языки. В процессе развития науки были разработаны формальные языки (системы счисления, алгебра, языки программирования и др.), основное отличие которых от естественных языков состоит в существовании строгих правил грамматики и синтаксиса.
Например, десятичную систему счисления можно рассматривать как формальный язык, имеющий алфавит (цифры) и позволяющий не только именовать и записывать объекты (числа), но и выполнять над ними арифметические операции по строго определенным правилам.
Существуют формальные языки, в которых в качестве знаков используют не буквы и цифры, а другие символы, например музыкальные ноты, изображения элементов электрических или логических схем, дорожные знаки, точки и тире (код азбуки Морзе).
Физическая реализация знаков в естественных и формальных языках может быть различной. Например, текст и числа могут быть напечатаны на бумаге, высвечены на экране монитора компьютера, записаны на магнитном или оптическом диске.
Знаки, используемые для обозначения фонем человеческого языка, называются буквами, а их совокупность – алфавитом языка.
Важно подчеркнуть, что понятия знака и алфавита можно отнести только к дискретным сообщениям!
К основным параметрам Средствам Отображения Информации следует отнести используемый алфавит, информационную емкость, разрешающую способность, быстродействие, точность воспроизведения информации, фотометрические параметры (яркость, контраст), надежность, стоимость, потребляемую мощность.
В информатике алфавит — это множество (как правило конечное) символов или букв, например латинских букв и цифр. Примером распространённого алфавита является двоичный алфавит . Конечная строка — это конечная последовательность букв алфавита. Например, двоичная строка — это строка из символов алфавита . Также возможно построение бесконечных последовательностей из букв алфавита.
Используемый алфавит и основание кода алфавита информационной модели определяются классом решаемых задач и задаются числом и типом знаков (цифр, букв, условных знаков и т. д.), количеством градаций размеров, яркости, ориентации символов, используемых цветов, частот мерцаний изображений и т. д.
Варианты преобразования сообщений. Преобразование непрерывных сигналов в непрерывные. Преобразование непрерывных сигналов в дискретные. Преобразование дискретных сигналов в дискретные. Преобразование дискретных сигналов в непрерывные.
Поскольку имеются два типа сообщений, между ними, очевидно, возможны четыре варианта преобразований:
Непрерывные в непрерывные:
Примерами устройств, в которых осуществляется преобразование типа N1→N2, являются: микрофон, магнитофон и видеомагнитофон, телекамера, радио- и телевизионный приемник, аналоговая вычислительная машина. Особенностью данного варианта преобразования является то, что оно всегда сопровождается частичной потерей информации. Потери связаны с помехами (шумами), которые порождает само информационное техническое устройство и которые воздействуют извне. Эти помехи примешиваются к основному сигналу и искажают его.
Непрерывные в дискретное , то есть дикретизация ( даёт в ряде случаев значительные преимущества при передаче, хранении и обработке информации)
Для преобразования непрерывного сигнала в дискретный используется процедура, которая называется квантованием.( Квантование — операция преобразования аналогового сигнала в дискретный сигнал. Квантование реализуется посредством разбиения диапазона значений аналогового сигнала на конечное число непересекающихся интервалов.
При квантовании происходит округление мгновенных значений аналогового сигнала до некоторой наперед заданной фиксированной величины (уровня). Различают квантование по времени и квантование по амплитуде сигнала.)
Теперь обсудим общий подход к преобразованию типа N>D. С математической точки зрения перевод сигнала из аналоговой формы в дискретную означает замену описывающей его непрерывной функции времени Z(t) на некотором отрезке [t1, t2] конечным множеством (массивом)
Дискретные в дискретные –
Преобразование типа D1>D2 состоит в переходе при представлении сигналов от одного алфавита к другому – такая операция носит название перекодировка и может осуществляться без потерь. Примерами ситуаций, в которых осуществляются подобные преобразования, могут быть: запись-считывание с компьютерных носителей информации; шифровка и дешифровка текста; вычисления на калькуляторе.
дискретных сигналов в непрерывные.
( устр-ва по типу модем — устройство для обмена информацией между компьютерами, которое осуществляет преобразование дискретных сигналов в непрерывные модулированные сигналы для передачи по линии связи и обратное преобразование (с демодуляцией) при приеме)
Сохранение информации в преобразованиях N>D иD>N обеспечивается именно благодаря участию в них дискретного представления. Другими словами, преобразование сообщений без потерь информации возможно только в том случае, если хотя бы одно из них является дискретным. В этом проявляется несимметричность видов сообщений и преимущество дискретной формы
Общее понятие кодирования информации
Познание окружающего мира начинается с восприятия его человеком с помощью органов чувств. Зрение, вкус, слух, обоняние, осязание доводят до нашего сознания информацию о самых разнообразных свойствах предметов, а также явлениях и процессах, происходящих вокруг нас. Эта информация поступает к нам в виде набора символов или сигналов. Однако если эти символы или сигналы никому не ясны, то информация будет бесполезной. Поэтому требуется язык общения, который будет понятен всем.
Естественные и формальные языки представления информации
Язык — это знаковая система для представления и передачи информации.
- естественные (например, мимика и жесты, музыка, живопись, речь человека);
- формальные (например, математическая символика, чертежи и схемы, нотная грамота, языки программирования).
Естественный язык можно формализовать. Так для формализации музыки изобрели нотную грамоту, для формализации речи создали национальные алфавиты (например, латинский ($26$ символов), русский ($33$ символа)), кроме этого арабские цифры, азбуку Морзе и т.д.
Попробуй обратиться за помощью к преподавателям
Естественные языки развивались веками и служили для общения людей между собой. Формальные языки разрабатываются для специальных применений.
Коммуникативный язык несет в себе логическую информацию, именно с помощью него человек преобразует получаемую информацию в знания и передает эти знания другим людям.
Алфавиты представления информации
Первобытные люди для обозначения каждого нового предмета придумывали новые имена. Для получения необходимого разнообразия имен, названий они стали комбинировать звуки таким образом, чтобы получить в результате слова. Так в ходе эволюции человека появилась идея создания конечного алфавита, т.е. некоторого фиксированного набора знаков, из которого можно составить как угодно много слов. Комбинация знаков алфавита называется словом. Из слов можно составлять фразы, которые будут нести определенную смысловую нагрузку.
Таким образом, алфавит – это упорядоченный набор символов или сигналов, который составляет основу языка.
Мощность алфавита — это количество составляющих его символов.
Задай вопрос специалистам и получи
ответ уже через 15 минут!
Человек в своей практике общения использует самые разнообразные языки (например, дорожная грамота, включающая в себя знаки дорожного движения и разметки). Прежде всего, это, конечно же, языки устной и письменной речи, в том числе и иностранные.
Кроме того, человек использует ряд языков профессионального назначения. К ним относятся языки математических и химических формул, обозначений электроники (например, схема электрической цепи), языки программирования. При этом каждый язык имеет свой алфавит.
С развитием технических средств передачи информации появилась необходимость использования помимо речевых алфавитов многих других. Одним из примеров первых алфавитов, используемых в технике, является азбука Морзе, в которой каждому знаку обычного алфавита соответствует набор точек и тире.
Общее понятие кодирования информации
Воспринимая информацию, человек стал стремиться зафиксировать ее таким образом, чтобы она стала понятной для других, представляя ее в той или иной форме.
Музыкальную тему композитор может наиграть на пианино, а затем записать с помощью нот. Образы, навеянные все той же мелодией, поэт может воплотить в виде стихотворения, хореограф выразить танцем, а художник — в картине.
Люди сохраняют свои знания, записывая их на различных носителях. Благодаря чему эти знания передаются не только в пространстве, но и во времени — от одного поколения к другому.
До наших дней дошли послания предков, которые с помощью различных символов пытались изобразить себя и свои поступки в памятниках и надписях. Примером могут служить наскальные рисунки (петроглифы), которые по сей день представляют загадку для ученых. Вероятнее всего, таким образом древние люди пытались вступить в контакт с будущими поколениями и сообщить о событиях их жизни.
Каждый народ имеет свой язык, состоящий из набора символов (букв): русский, английский, японский и многие другие. Об этом уже упоминалось ранее.
Представление информации с помощью какого-либо языка часто называют кодированием.
Код — это набор символов либо условных обозначений, используемый для представления информации.
Алфавит кодирования содержит полный набор кодов.
Кодирование — это процесс представления информации с помощью кода.
Так водитель пытается передать сигнал с помощью гудка или мигания фар. В данном случае гудок (его наличие или отсутствие) – это код, а в случае световой сигнализации кодом будет являться мигание фар или его отсутствие. Пешеход встречается с кодированием информации при переходе дороги по сигналу светофора. Код определяет цвет светофора — красный, желтый, зеленый.
Естественный язык, на котором мы общаемся, тоже представляет собой код, называемый алфавитом. Во время устной речи этот код передается звуками, при письменной — буквами. Причем одну и ту же информацию можно представить различными способами. К примеру, запись разговора можно закодировать на бумажном носителе двумя способами: с помощью букв или специальных стенографических знаков.
В более узком смысле под кодированием часто понимают переход от одной формы представления информации к другой, которая более удобна при хранении, передаче или обработке.
В процессе развития технических средств появлялись новые способы кодирования информации. Так во второй половине XIX века американский изобретатель Сэмюэль Морзе придумал удивительно простой код, который применяется до сих пор. Используя этот код, информацию можно представить в виде: длинного сигнала (тире), короткого сигнала (точки) и отсутствия сигнала (паузы) для разделения букв. Таким образом, принцип кодирования сводился к использованию набора символов, расположенных в строго определенном порядке.
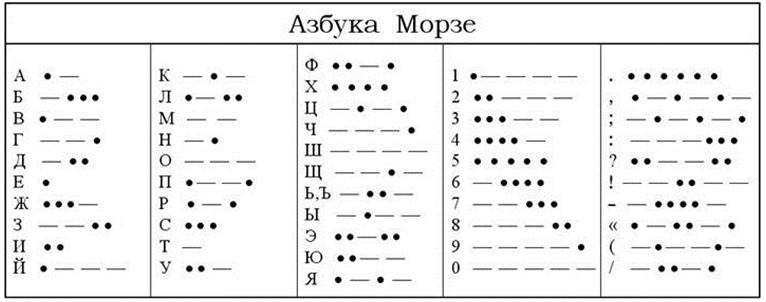
Люди во все времена пытались найти способы быстрого обмена сообщениями. Для этого существовали гонцы, использовались почтовые голуби. Разные народы использовали различные способы оповещения о надвигающейся опасности: это и барабанный бой, и дым костров, и набат колокола, и флаги определенных цветов и пр. Однако при передаче таким способом информации требовалась предварительная договоренность, чтобы принимаемые сообщения были поняты.
Знаменитый немецкий ученый Готфрид Вильгельм Лейбниц предложил еще в XVII веке уникальную по своей простоте систему представления чисел, основанную на использовании вычислений с помощью двоек.
В настоящее время этот способ представления информации с помощью языка, в состав которого входит всего два символа: $0$ и $1$, называется двоичным кодированием информации и широко используется в технических устройствах, в том числе и в компьютере. Эти два символа $0$ и $1$ принято называть двоичными цифрами или битами (от англ. bit — Binary Digit — двоичный знак).
Инженеров такой способ кодирования информации привлек простотой технической реализации, поскольку при помощи $0$ и $1$ ($0$ – сигнала нет, $1$ – сигнал есть) можно закодировать любое сообщение.
Каждому человеку ежедневно в бытовых условиях приходится сталкиваться с устройствами, которые могут находиться только в двух устойчивых состояниях: включено или выключено. И это хорошо известные всем выключатели. Однако изобрести выключатель, который был бы способен устойчиво и быстро переключаться в любое из $10$ состояний, оказалось невозможно. В итоге после ряда неудачных попыток разработчики сделали вывод о невозможности создания компьютера на основе десятичной системы счисления. Поэтому представление чисел в компьютере осуществляется с помощью двоичной системы счисления.
Способ кодирования информации зависит от цели, которая при этом должна быть достигнута. Целью может являться сокращение записи, засекречивание (шифровка) информации, или, напротив, достижение взаимопонимания. Например, система дорожных знаков, флажковая азбука на флоте, специальные научные языки и символы ― химические, математические, медицинские и др., предназначены для того, чтобы люди могли общаться и понимать друг друга. От того, как представлена информация, зависит способ ее обработки, хранения, передачи и т.д.
Так и не нашли ответ
на свой вопрос?
Просто напиши с чем тебе
нужна помощь
Информатика. Информация. Алфавит.
Информатика – это наука об информационных процессах, о моделях, об алгоритмах и алгоритмизации, о программах и программировании, об исполнителях алгоритмов и различных исполняющих системах об их использовании в обществе, в природе, в познании [1].
3 основыне ветви:
1.Теоретическая информатика изучает теоретические проблемы информационных сред.
2.Практическая информатика изучает практические проблемы информационных сред.
3.Техническая информатика изучает технические проблемы информационных сред.
Алфавит– конечное множество различных знаков, символов, для которых определена операция конкатенации ( присоединения символа к символу или цепочке символов); с ее помощью по определенным правилам соединения символов и слов можно получать слова (цепочки знаков) и словосочетания (цепочки слов) в этом алфавите (над этим алфавитом).
Буквой или знаком называется любой элемент x.
Длиной |p| некоторого слова p над алфавитом Х называется число составляющих его символов.
Информация– это некоторая упорядоченная последовательность сообщений, имеющих конкретный смысл.
14 Основные свойства информации:
- полнота;
- актуальность;
- адекватность;
- понятность;
- достоверность;
- массовость;
- устойчивость;
- ценность и др.
· Информация актуализируется с помощью различной формы сообщений – определенного вида сигналов, символов.
· Информация по отношению к источнику или приемнику бывает трех типов: входная, выходная и внутренняя.
· Информация по отношению к конечному результату бывает исходная, промежуточная и результирующая.
· Информация по стадии ее использования бывает первичная и вторичная.
· Информация по ее полноте бывает избыточная, достаточная и недостаточная.
· Информация по доступу к ней бывает открытая и закрытая.
Мера информации.
Любые сообщения измеряются в байтах, килобайтах, мегабайтах, гигабайтах, терабайтах, петабайтах и эксабайтах, а кодируются, например, в компьютере, с помощью алфавита из нулей и единиц, записываются и реализуются в ЭВМ в битах.
Приведем основные соотношения между единицами измерения сообщений:
1 бит (binary digit– двоичное число) = 0 или 1,
1 байт = 8 бит,
1 килобайт (1Кб) = 2 13 бит,
1 мегабайт (1Мб) = 2 23 бит,
1 гигабайт (1Гб) = 2 33 бит,
1 терабайт (1Тб) = 2 43 бит,
1 петабайт (1Пб) = 2 53 бит,
1 эксабайт (1Эб) = 2 63 бит.
Мера информации– критерий оценки количества информации. Обычно она задана некоторой неотрицательной функцией, определенной на множестве событий и являющейся аддитивной, то есть мера конечного объединения событий (множеств) равна сумме мер каждого события.
Рассмотрим различные меры информации. Возьмем меру Р. Хартли. Пусть известны N состояний системы S (N — число опытов с различными, равновозможными, последовательными состояниями системы). Если каждое состояние системы закодировать двоичными кодами, то длину кода dнеобходимо выбрать так, чтобы число всех различных комбинаций было бы не меньше, чем N:

Логарифмируя это неравенство, можно записать:

Наименьшее решение этого неравенства или мера разнообразия множества состояний системы задается формулой Р. Хартли:
Если во множестве X =
Уменьшение Н говорит об уменьшении разнообразия состояний N системы.
Увеличение Н говорит об увеличении разнообразия состояний N системы.
Мера Хартли подходит лишь для идеальных, абстрактных систем, так как в реальных системах состояния системы не равновероятны.
Для таких систем используют более подходящую меру К. Шеннона. Мера Шеннона оценивает информацию отвлеченно от ее смысла.
Презентация на тему «Язык и информация. Алфавит, буква, слово в языке. Кодирование»

- Скачать презентацию (0.07 Мб) 32 загрузки 2.0 оценка

Содержание

Тема урока
Язык и информация. Алфавит, буква, слово в языке. Кодирование.
Изучив эту тему, вы узнаете:
Внутренние и внешние языки Языки представления данных Что такое алфавит, мощность алфавита Что такое информационный вес символа в алфавите Как измерить информационный объем текста с алфавитной точки зрения Что такое кодирование и декодирование
Рассмотрим понятия:
Опорные Информация Язык, алфавит Символ Сигнал Новые Язык представления данных Синтаксис, семантика, прагматика Код, кодирование, декодирование Двоичный код Кодовая таблица Бит, байт, файл
Классификация информации по структуре и типу
Информация, с которой имеет дело человек
Образная информация – это сохраненные в памяти ощущения человека от контакта с источником; она воспринимается всеми органами чувств человека. Символьная информация – воспринимаемая человеком в речевой или письменной (знаковой) форме. Представлениеинформации может осуществляться с помощью языков.
Естественные языки Русский язык Немецкий язык Французский язык Болгарский язык Языки информатики Языки двоичных кодов Командные языки ОС Языки представления знаний Языки программирования Другие языки: — Язык математики — Язык химии — Язык музыки — Язык дорожных знаков Формальные языки
Язык – это множество символов и совокупность правил, определяющих способы составления из этих символов осмысленных сообщений. Естественные языки – это исторически сложившиеся языки национальной речи. Формальные языки – это искусственно созданные языки для профессионального применения. Для них характерна принадлежность к ограниченной предметной области (математика, химия, музыка и пр.) Алфавит – множество используемых символов. Последовательность символов образует слово на этом языке. Синтаксис – правила записи языковых конструкций (текста на языке). Семантика – смысловая сторона языковых конструкций. Прагматика – практические последствия применения текста на данном языке.
Языки, используемые при работе ЭВМ
Информацию циркулирующую в компьютере, можно разделить на два вида: обрабатываемая информация (данные) и информация, управляющая работой компьютера (команды, программы, операторы). Способ представления данных в компьютере называется языком представления данных. (необходим для определения количества информации).
Языки представления данных
— устройство ЭВМ, которое используется для записи, хранения и выдачи по запросу информации, необходимой для решения задач на ЭВМ. Внутреннее представление – На носителях информации в компьютере, т.е. памяти, в линиях передачи информации. Язык двоичных кодов. Внешнее представление – ориентировано на человека (алфавиты естественных языков, десятичная система счисления, традиционная математическая символика).
Отображение множества состояний источника во множество состояний носителя называется способом кодирования. Любая информация хранится в виде кодов. Языком представления данных ЭВМ является язык двоичных кодов. «0100000100101011» = 16683 = «А+» Для разных типов данных используются разные языки внутреннего представления. Общим является лишь двоичный алфавит: 0 и 1. Алфавит – это таблица для кодирования букв. Стандарт ASCII – алфавит для компьютера.
Единицы измерения информации
Наименьшая единица количества информации — 1бит Наименьшая единица измерения информации – 1 байт Наименьшая единица хранения информации — файл 1 бит = 0/1 1 байт = 8 бит = 28бит = 256 значений 1 Кбайт = 1024 байт 1 Мбайт = 1024 Кбайт = 1 048 576 байт; 1 Гбайт = 1024 Мбайт = 1 073 741 824 байт; 1 Тбайт = 1024 Гбайт = 1 099 511 627 776 байт.
Что такое алфавит с точки зрения информатики
Например, для алфавита строки составляют его замыкание Клини (где ε обозначает пустую строку).
Алфавиты играют важную роль в теории формальных языков, автоматов и полуавтоматов. В большинстве случаев для определения сущности автоматов, таких как детерминированный конечный автомат (ДКА), требуется задать алфавит, из которого составляются входные строки для автомата.

- Дополнить статью (статья слишком короткая либо содержит лишь словарное определение).
- Найти и оформить в виде сносок ссылки на авторитетные источники, подтверждающие написанное.
Wikimedia Foundation . 2010 .
Смотреть что такое «Алфавит (информатика)» в других словарях:
Алфавит (математика) — Эту страницу предлагается объединить с Алфавит (информатика). Пояснение причин и обсуждение на странице Википедия:К объединению/14 сентября 2012. Обсуждение длится одну неделю (или дольше, если оно идёт медленно). Дата начала обсуждения 2012 09… … Википедия
ДРАКОН — Эта статья предлагается к удалению. Пояснение причин и соответствующее обсуждение вы можете найти на странице Википедия:К удалению/28 сентября 2012. Пока процесс обсуждения не завершён, статью мож … Википедия
ДРАКОН (алгоритмический язык) — У этого термина существуют и другие значения, см. Дракон (значения). Пример блок схемы алгоритма на языке ДРАКОН дракон схемы ДРАКОН (Дружелюбный Русский Алгоритмический язык, Который Обеспечивает Наглядность) визуальный… … Википедия
Мнемоника — Содержание 1 Основной метод запоминания в современной мнемонике 2 История … Википедия
Информация — (Information) Информация это сведения о чем либо Понятие и виды информации, передача и обработка, поиск и хранение информации Содержание >>>>>>>>>>>> … Энциклопедия инвестора
ОСАНКА — привычное положение тела человека в покое и при движении. При правильной О. тело постоянно и без напряжения сохраняет выпрямленное положение, плечи слегка отведены назад, живот подобран. Такая О. делает фигуру красивой, способствует правильному… … Российская педагогическая энциклопедия
ОСНОВЫ ИНФОРМАТИКИ И ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ — (ОИВТ), уч предмет, введенный в ср у ч заведения Рос Федерации с 1985/86 у ч г. Предусматривает изучение законов и методов сбора, передачи и обработки информации с помощью электронной вычислит техники Цель обучения ОИВТ формирование «компьютерной … Российская педагогическая энциклопедия
ЗНАК — материальный объект (артефакт), выступающий в коммуникативном или трансляционном процессе аналогом другого объекта (предмета, свойства, явления, понятия, действия), замещающий его. 3. является осн. средством культуры, с его помощью… … Энциклопедия культурологии
Вертикальная черта — | ¦ Вертикальная черта Пунктуация апостроф ( … Википедия
Список терминов, относящихся к алгоритмам и структурам данных — Это служебный список статей, созданный для координации работ по развитию темы. Данное предупреждение не устанавливается на информационные списки и глоссарии … Википедия
Измерение информации
Алфавитный подход
Алфавитный подход используется для измерения количества информации в тексте, представленном в виде последовательности символов некоторого алфавита. Такой подход не связан с содержанием текста. Количество информации в этом случае называется информационным объемом текста, который пропорционален размеру текста — количеству символов, составляющих текст. Иногда данный подход к измерению информации называют объемным подходом.
Каждый символ текста несет определенное количество информации. Его называют информационным весом символа. Поэтому информационный объем текста равен сумме информационных весов всех символов, составляющих текст.

Здесь предполагается, что текст — это последовательная цепочка пронумерованных символов. В формуле (1) i1 обозначает информационный вес первого символа текста, i2 — информационный вес второго символа текста и т.д.; K — размер текста, т.е. полное число символов в тексте.
Все множество различных символов, используемых для записи текстов, называется алфавитом. Размер алфавита — целое число, которое называется мощностью алфавита. Следует иметь в виду, что в алфавит входят не только буквы определенного языка, но все другие символы, которые могут использоваться в тексте: цифры, знаки препинания, различные скобки, пробел и пр.
Определение информационных весов символов может происходить в двух приближениях:
1) в предположении равной вероятности (одинаковой частоты встречаемости) любого символа в тексте;
2) с учетом разной вероятности (разной частоты встречаемости) различных символов в тексте.
Приближение равной вероятности символов в тексте
Если допустить, что все символы алфавита в любом тексте появляются с одинаковой частотой, то информационный вес всех символов будет одинаковым. Пусть N — мощность алфавита. Тогда доля любого символа в тексте составляет 1/N-ю часть текста. По определению вероятности (см. “Измерение информации. Содержательный подход”  ) эта величина равна вероятности появления символа в каждой позиции текста:
) эта величина равна вероятности появления символа в каждой позиции текста:
Согласно формуле К.Шеннона (см. “Измерение информации. Содержательный подход” ), количество информации, которое несет символ, вычисляется следующим образом:
Следовательно, информационный вес символа (i) и мощность алфавита (N) связаны между собой по формуле Хартли (см. “Измерение информации. Содержательный подход” )
Зная информационный вес одного символа (i) и размер текста, выраженный количеством символов (K), можно вычислить информационный объем текста по формуле:
Эта формула есть частный вариант формулы (1), в случае, когда все символы имеют одинаковый информационный вес.

Из формулы (2) следует, что при N = 2 (двоичный алфавит) информационный вес одного символа равен 1 биту.
С позиции алфавитного подхода к измерению информации 1 бит — это информационный вес символа из двоичного алфавита.
Более крупной единицей измерения информации является байт.
1 байт — это информационный вес символа из алфавита мощностью 256.
Поскольку 256 = 2 8 , то из формулы Хартли следует связь между битом и байтом:
Отсюда: i = 8 бит = 1 байт
Для представления текстов, хранимых и обрабатываемых в компьютере, чаще всего используется алфавит мощностью 256 символов. Следовательно,
1 символ такого текста “весит” 1 байт.
Помимо бита и байта, для измерения информации применяются и более крупные единицы:
1 Кб (килобайт) = 2 10 байт = 1024 байта,
1 Мб (мегабайт) = 2 10 Кб = 1024 Кб,
1 Гб (гигабайт) = 2 10 Мб = 1024 Мб.
Приближение разной вероятности встречаемости символов в тексте
В этом приближении учитывается, что в реальном тексте разные символы встречаются с разной частотой. Отсюда следует, что вероятности появления разных символов в определенной позиции текста различны и, следовательно, различаются их информационные веса.
Статистический анализ русских текстов показывает, что частота появления буквы “о” составляет 0,09. Это значит, что на каждые 100 символов буква “о” в среднем встречается 9 раз. Это же число обозначает вероятность появления буквы “о” в определенной позиции текста: po = 0,09. Отсюда следует, что информационный вес буквы “о” в русском тексте равен:

Самой редкой в текстах буквой является буква “ф”. Ее частота равна 0,002. Отсюда:

Отсюда следует качественный вывод: информационный вес редких букв больше, чем вес часто встречающихся букв.
Как же вычислить информационный объем текста с учетом разных информационных весов символов алфавита? Делается это по следующей формуле:

Здесь N — размер (мощность) алфавита; nj — число повторений символа номер j в тексте; ij — информационный вес символа номер j.
Методические рекомендации
Алфавитный подход в курсе информатики основой школы
В курсе информатики в основной школе знакомство учащихся с алфавитным подходом к измерению информации чаще всего происходит в контексте компьютерного представления информации. Основное утверждение звучит так:
Количество информации измеряется размером двоичного кода, с помощью которого эта информация представлена
Поскольку любые виды информации представляются в компьютерной памяти в форме двоичного кода, то это определение универсально. Оно справедливо для символьной, числовой, графической и звуковой информации.

Один знак (разряд) двоичного кода несет 1 бит информации.
При объяснении способа измерения информационного объема текста в базовом курсе информатики данный вопрос раскрывается через следующую последовательность понятий: алфавит — размер двоичного кода символа — информационный объем текста.
Логика рассуждений разворачивается от частных примеров к получению общего правила. Пусть в алфавите некоторого языка имеется всего 4 символа. Обозначим их: ,
,  ,
,  ,
,  . Эти символы можно закодировать с помощью четырех двухразрядных двоичных кодов: — 00, — 01, — 10, — 11. Здесь использованы все варианты размещений из двух символов по два, число которых равно 2 2 = 4. Отсюда делается вывод: информационный вес символа из 4-символьного алфавита равен двум битам.
. Эти символы можно закодировать с помощью четырех двухразрядных двоичных кодов: — 00, — 01, — 10, — 11. Здесь использованы все варианты размещений из двух символов по два, число которых равно 2 2 = 4. Отсюда делается вывод: информационный вес символа из 4-символьного алфавита равен двум битам.
Следующий частный случай — 8-символьный алфавит, каждый символ которого можно закодировать 3-разрядным двоичным кодом, поскольку число размещений из двух знаков группами по 3 равно 2 3 = 8. Следовательно, информационный вес символа из 8-символьного алфавита равен 3 битам. И т.д.
Обобщая частные примеры, получаем общее правило: с помощью b-разрядного двоичного кода можно закодировать алфавит, состоящий из N = 2 b — символов.
Пример 1. Для записи текста используются только строчные буквы русского алфавита и “пробел” для разделения слов. Какой информационный объем имеет текст, состоящий из 2000 символов (одна печатная страница)?
Решение. В русском алфавите 33 буквы. Сократив его на две буквы (например, “ё” и “й”) и введя символ пробела, получаем очень удобное число символов — 32. Используя приближение равной вероятности символов, запишем формулу Хартли:
Отсюда: i = 5 бит — информационный вес каждого символа русского алфавита. Тогда информационный объем всего текста равен:
I = 2000 · 5 = 10 000 бит
Пример 2. Вычислить информационный объем текста размером в 2000 символов, в записи которого использован алфавит компьютерного представления текстов мощностью 256.
Решение. В данном алфавите информационный вес каждого символа равен 1 байту (8 бит). Следовательно, информационный объем текста равен 2000 байт.
В практических заданиях по данной теме важно отрабатывать навыки учеников в пересчете количества информации в разные единицы: биты — байты — килобайты — мегабайты — гигабайты. Если пересчитать информационный объем текста из примера 2 в килобайты, то получим:
2000 байт = 2000/1024  1,9531 Кб
1,9531 Кб
Пример 3. Объем сообщения, содержащего 2048 символов, составил 1/512 часть мегабайта. Каков размер алфавита, с помощью которого записано сообщение?
Решение. Переведем информационный объем сообщения из мегабайтов в биты. Для этого данную величину умножим дважды на 1024 (получим байты) и один раз — на 8:
I = 1/512 · 1024 · 1024 · 8 = 16 384 бита.
Поскольку такой объем информации несут 1024 символа (К), то на один символ приходится:
Отсюда следует, что размер (мощность) использованного алфавита равен 2 16 = 65 536 символов.
Объемный подход в курсе информатики в старших классах
Изучая информатику в 10–11-х классах на базовом общеобразовательном уровне, можно оставить знания учащихся об объемном подходе к измерению информации на том же уровне, что описан выше, т.е. в контексте объема двоичного компьютерного кода.
При изучении информатики на профильном уровне объемный подход следует рассматривать с более общих математических позиций, с использованием представлений о частотности символов в тексте, о вероятностях и связи вероятностей с информационными весами символов.
Знание этих вопросов оказывается важным для более глубокого понимания различия в использовании равномерного и неравномерного двоичного кодирования (см. “Кодирование информации” ), для понимания некоторых приемов сжатия данных (см. “Сжатие данных” ) и алгоритмов криптографии (см. “Криптография” ).
Пример 4. В алфавите племени МУМУ всего 4 буквы (А, У, М, К), один знак препинания (точка) и для разделения слов используется пробел. Подсчитали, что в популярном романе “Мумука” содержится всего 10 000 знаков, из них: букв А — 4000, букв У — 1000, букв М — 2000, букв К — 1500, точек — 500, пробелов — 1000. Какой объем информации содержит книга?
Решение. Поскольку объем книги достаточно большой, то можно допустить, что вычисленная по ней частота встречаемости в тексте каждого из символов алфавита характерна для любого текста на языке МУМУ. Подсчитаем частоту встречаемости каждого символа во всем тексте книги (т.е. вероятность) и информационные веса символов


Общий объем информации в книге вычислим как сумму произведений информационного веса каждого символа на число повторений этого символа в книге:
Лекция 5. Информация и алфавит
Рассматривая формы представления информации (сообщений), отметили то обстоятельство, что естественной для органов чувств человека являетя аналоговая форма представления сообщений. Универсальной все же следует считать дискретную форму представления информации с помощью некоторого набора знаков. В частности, именно таким образом представленная информация обрабатывается компьютером, передается по компьютерным линиям связи.
Сообщение есть последовательность знаков алфавита. При передаче сообщения возникает проблемараспознавания знака: каким образомпрочитатьсообщение, то есть по полученным сигналам установить исходную (предназначенную для передачи) последовательность знаков.
В устной речи это достигается посредством использования различных фонем (звуков), по которым и отличаются знаки речи. В письменности это достигается с помощью различного начертания букв и дальнейшего анализа написанного.
Как данная задача может решаться техническим устройством, рассмотрим позже. Сейчас для нас важно, что можно реализовать некоторую процедуру, посредством которой можно выделить из сообщения тот или иной знак.
Необходимо отметить, что для нас (для приемника сообщения) появление конкретного знака (буквы) в конкретном месте сообщения – событие случайное. Следовательно, узнавание (отождествление с эталоном) знака требует получения некоторой порции информации, то есть снятия неопределенности, связанной с появлением этого знака. Эту информацию можно связать с самим знаком и считать, что знак несет в себе (содержит) некоторое количество информации.
Попробуем оценить это количество информации.
Начнем с самого грубого приближения, будем называть его нулевымприближениеми обозначать индексом «0» у получаемых величин.
Предположим, что появление всех знаков (букв) алфавита в сообщении равновероятно(в реальности это не так).
В английском алфавите с учетом знака «пробел» имеется 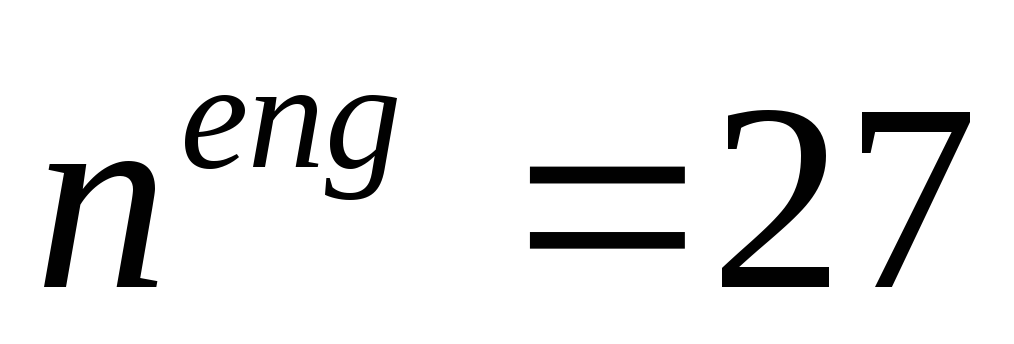 знаков, для русского алфавита с учетом пробела
знаков, для русского алфавита с учетом пробела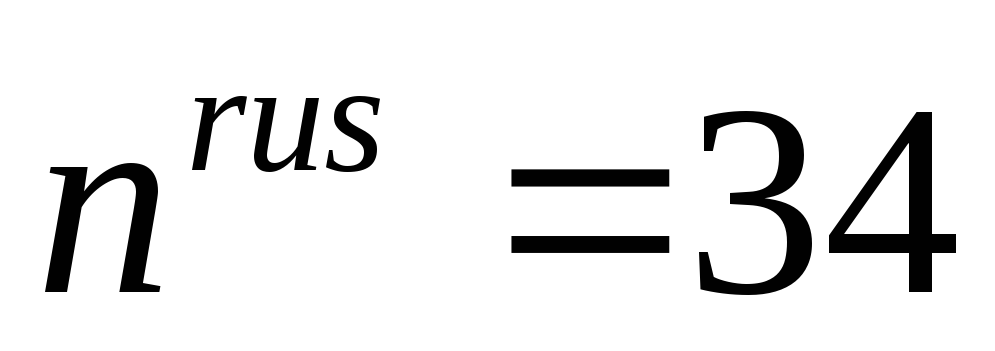 . Для оценки информации, приходящейся на один знак алфавита, применим формулу Хартли:
. Для оценки информации, приходящейся на один знак алфавита, применим формулу Хартли:
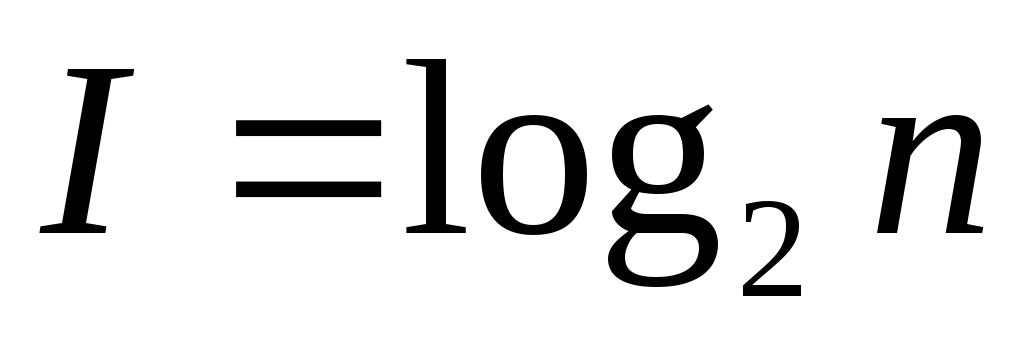 .
.
Таким образом,  ;
;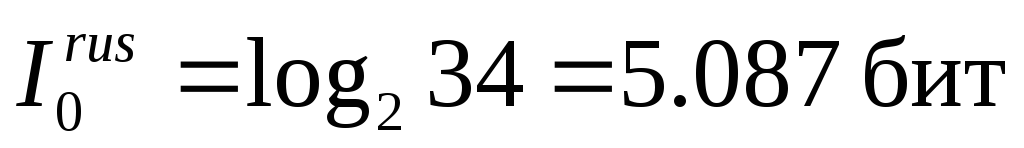 .
.
Получается, что в нулевом приближении со знаком русского алфавита в среднем связано больше информации, чем со знаком английского алфавита. Это, безусловно не означает, что английский язык – язык Шекспира и Диккенса – беднее, чем язык Пушкина и Достоевского. Лингвистическое богатство языка определяется количеством слов и их сочетаний, и никак не связано с числом букв в алфавите.
Продолжим анализировать количество информации, связанное с одним символом алфавита.
В качестве следующего (первого)приближения, уточняющего исходное нулевое приближение, попробуем учесть то обстоятельство, что относительная частота, то есть вероятность появления различных букв в тексте (то есть сообщении) различна.
Рассмотрим следующий набор знаков на основе русского алфавита. В рассматриваемый алфавит включен знак «пробел» для разделения слов. Кроме того, в этом алфавите буквы «е» и «ё» не различаются (часто так принято в печатных текстах), знаки «ь» и «ъ» также не различаются (так принято в телеграфном кодировании). В результате получаем алфавит из 32 знаков. Рассмотрим таблицу средних частот появления знаков такого алфавита, то есть таблицу вероятностей появления этих знаков в сообщениях (табл. 4). Эта таблица построена на основе статистического исследования, обработки большого количества различных сообщений.
Табл. 4. Таблица вероятностей появления знаков русского алфавита в сообщениях
Аналогичные подсчеты можно произвести и для других языков.
Если расположить все буквы языка в порядке убывания вероятностей их появления, то получатся следующие последовательности:
«Пробел», E, T, A, O, N, R, …
«Пробел», E, N, I, S, T, R, …
«Пробел», E, S, A, N, I, T, …
Для оценки информации, связанной с выбором одного знака алфавита с учетом неравной вероятности их появления в сообщении (текстах) можно воспользоваться формулой (5.2) из предыдущей лекции:
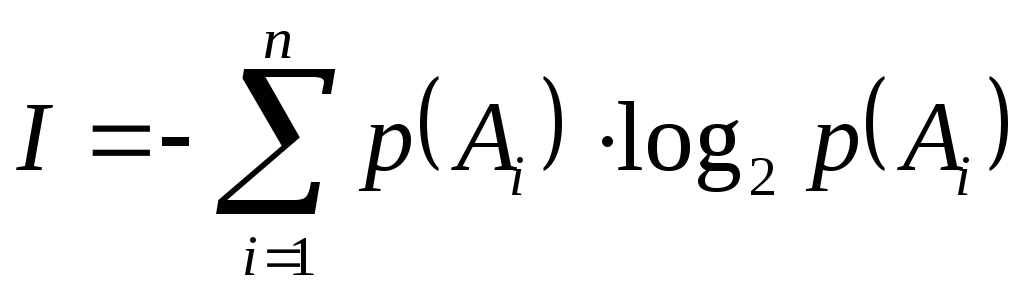 .
.
Из этой формулы, в частности, следует, что если 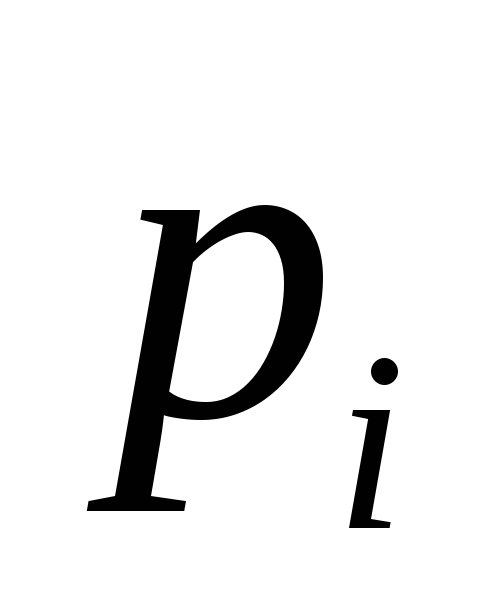 – вероятность (относительная частота – в большом количестве сообщений) знака номер
– вероятность (относительная частота – в большом количестве сообщений) знака номер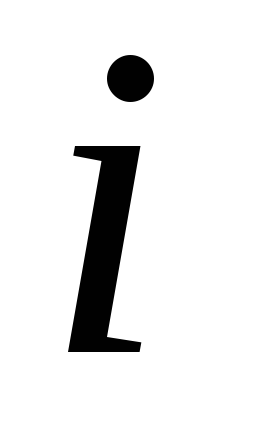 данного алфавита из
данного алфавита из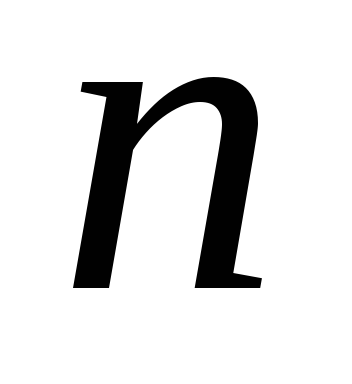 знаков, тосреднее количество информации, приходящейся на один знак, равно:
знаков, тосреднее количество информации, приходящейся на один знак, равно:
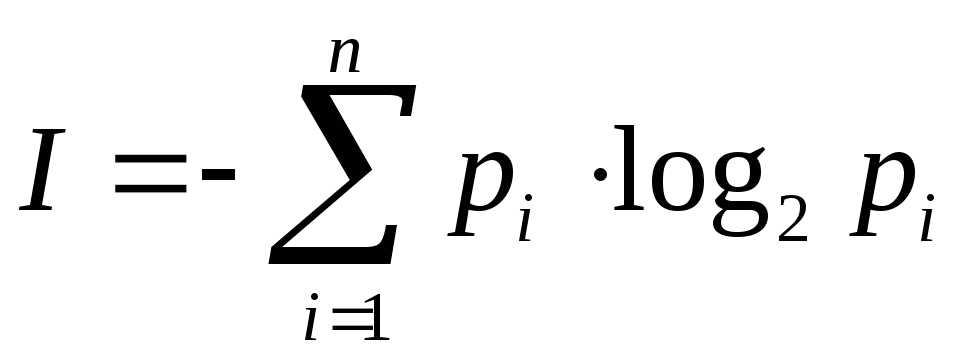 . (6.1)
. (6.1)
Формула (6.1) – это знаменитая формула К. Шеннона, с работы которого «Математическая теория связи» (1948 год) принято начинать отсчет возраста информатики, как самостоятельной науки.
Следует отметить, что и в нашей стране практически в то же время велись подобные исследования. Например, в том же 1948 году вышла работа А.Н. Колмогорова «Математическая теория передачи информации».
В общем случае информация, которая содержится в сообщении, может зависеть от того, в какой момент времени оно достигает приемника. Например, несвоевременное сообщение о погоде, очевидно, не несет той же информации, что и своевременное.
Однако возможно существование сообщений, в которых содержащаяся в них информация не зависит от времени поступления. В частности, такая ситуация реализуется в том случае, если вероятность встретить в сообщении какой-либо знак номер 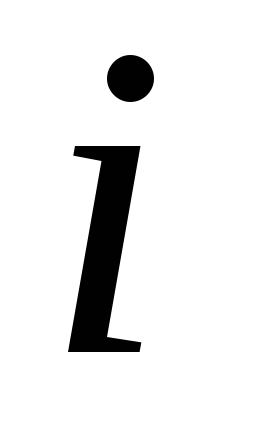 не зависит от времени, точнее, она одинакова во все моменты времени и равна относительной частоте появления этого знака
не зависит от времени, точнее, она одинакова во все моменты времени и равна относительной частоте появления этого знака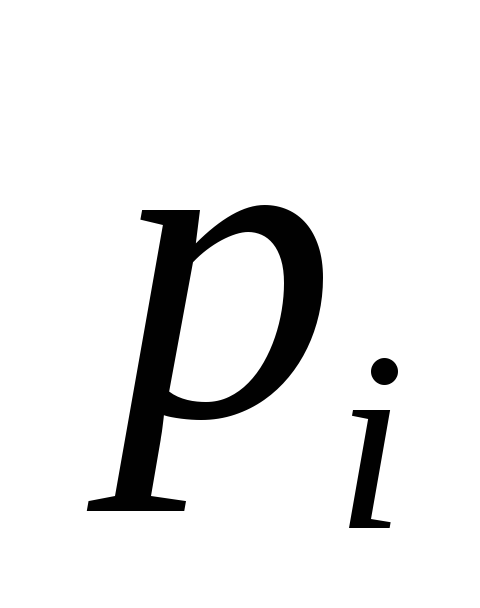 во всей последовательности знаков. Поэтому вероятности знаков (относительные частоты) определяются для сообщений (текстов), содержащих большое число символов с тем, чтобы проявились статистические закономерности, и далее эти вероятности считаются неизменными во всех сообщениях данного источника.
во всей последовательности знаков. Поэтому вероятности знаков (относительные частоты) определяются для сообщений (текстов), содержащих большое число символов с тем, чтобы проявились статистические закономерности, и далее эти вероятности считаются неизменными во всех сообщениях данного источника.
Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем, называются шенноновскими сообщениями, а порождающий их отправитель – шенноновским источником.
Если сообщение является шенноновским, то набор знаков (алфавит) и связанная с каждым знаком информация известны заранее. В этом случае интерпретация сообщения, представляющего собой последовательность сигналов, сводится к задаче распознавания знака, то есть к выявлению, какой именно знак находится в данном месте сообщения. При этом количество информации, содержащееся в знаке, служит мерой затрат по его выявлению.
Теория информации строится именно для шенноновских сообщений, поэтому в дальнейшем мы будем считать это исходным положением (условием использования) теории и рассматривать только такие сообщения.
Формула Шеннона позволяет оценить количество информации на один знак в алфавите уже в первом приближении. Применение формулы Шеннона (6.1) к алфавитам дает следующие средние значения информации, приходящейся на один знак:
для русского языка:
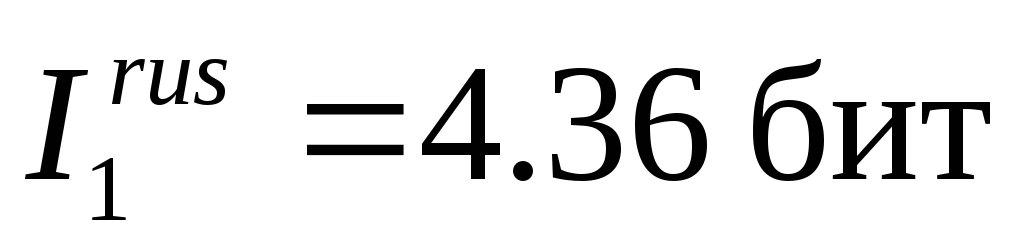 ;
;
для английского языка:
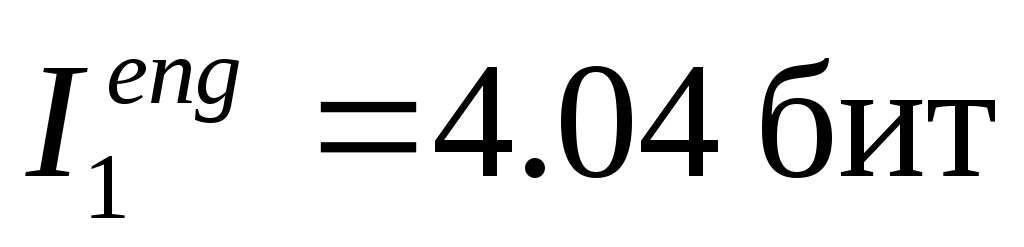 ;
;
для французского языка:
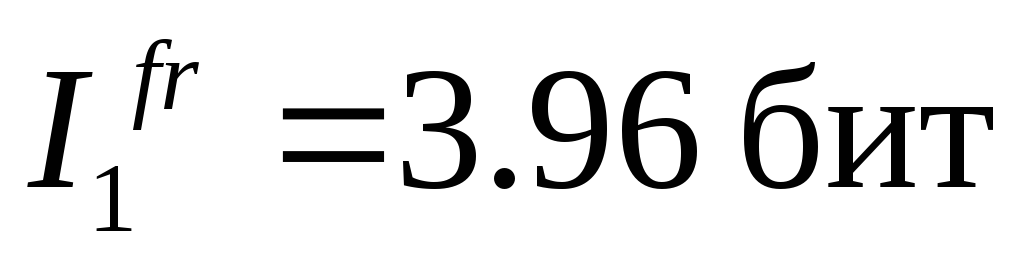 ;
;
для немецкого языка:
 ;
;
для испанского языка:
 .
.
Таким образом, учет различий в вероятностях появления букв в сообщениях приводит к уменьшению среднего информационного содержаниябуквы.
Английский, немецкий, французский, испанский языки принадлежат к романо-германской языковой группе и основаны на одном алфавите. Несовпадение значений средней информации на один знак в этих языках является следствием того, что частоты появления одинаковых букв в разных языках различны.
Следующими (вторыми, третьими) приближениями при оценке значения информации, приходящейся на знак алфавита, должен быть учет корреляций, то есть учет связей между буквами в словах. Дело в том, что буквы в словах появляются не в любых сочетаниях; это понижает неопределенность при угадывании следующей буквы после нескольких букв. Например, в русском языке нет слов, в которых встречается сочетание «щц» или «фж». И напротив, после некоторых сочетаний букв можно с большой определенностью судить о появлении следующей буквы. Например, после распространенного сочетания «пр-» всегда следует гласная буква, а их в русском языке всего 10; следовательно, вероятность угадывания следующей буквы 0.1, а не .
.
Учет в английских словах двухбуквенных сочетаний понижает среднюю информацию на знак до значения  , учет трехбуквенных сочетаний понижает среднюю информацию на знак до значения
, учет трехбуквенных сочетаний понижает среднюю информацию на знак до значения . К. Шеннон сумел приблизительно оценить
. К. Шеннон сумел приблизительно оценить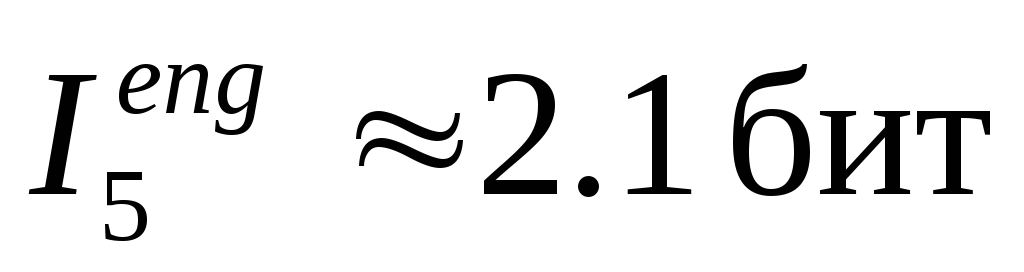 и
и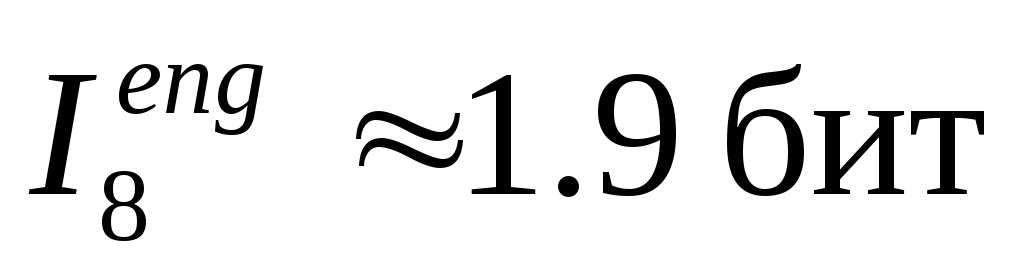 .
.
Аналогичные исследования для русского языка показывают, что учет двухбуквенных сочетаний понижает среднюю информацию на знак до значения  , а учет трехбуквенных сочетаний понижает среднюю информацию на знак до значения
, а учет трехбуквенных сочетаний понижает среднюю информацию на знак до значения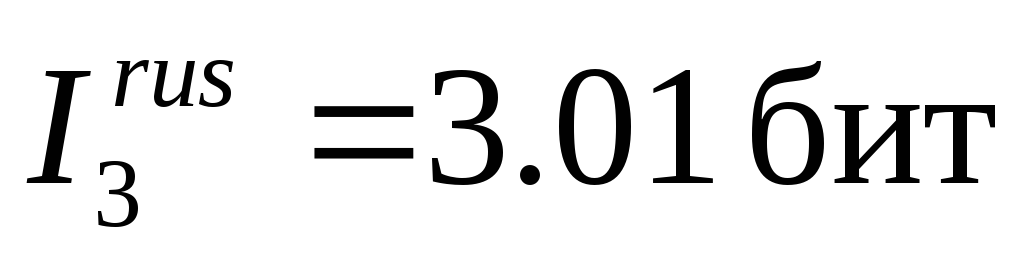 .
.
Последовательность  ,
,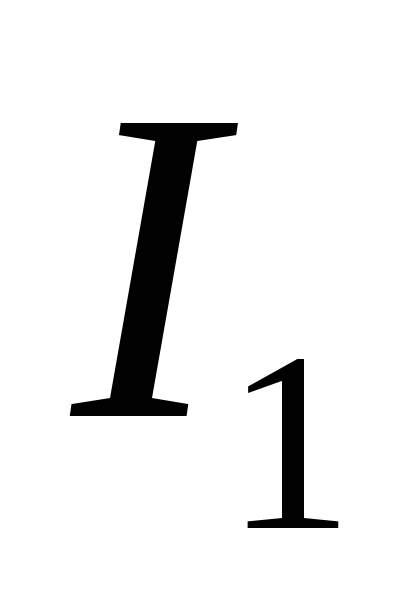 ,
,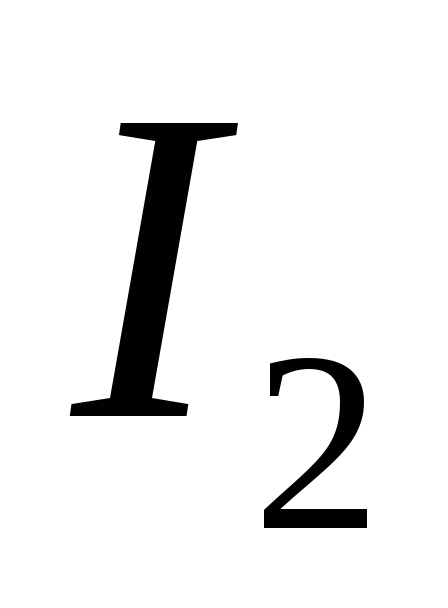 , … является убывающей в любом языке. Эстраполируя эту последовательность на учет бесконечного числа корреляций, можно оценить предельную информацию на знак в данном языке
, … является убывающей в любом языке. Эстраполируя эту последовательность на учет бесконечного числа корреляций, можно оценить предельную информацию на знак в данном языке , которая будет отражатьминимальную неопределенность, связанную с выбором знака алфавита без учета семантических (смысловых) особенностей языка.
, которая будет отражатьминимальную неопределенность, связанную с выбором знака алфавита без учета семантических (смысловых) особенностей языка.
Величина средней информации на знак в нулевом приближении 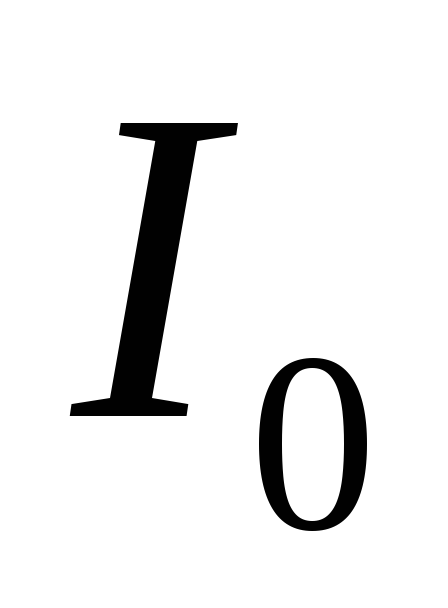 является другим предельным случаем, поскольку характеризуетнаибольшую информацию, которая может содержаться в знаке данного алфавита.
является другим предельным случаем, поскольку характеризуетнаибольшую информацию, которая может содержаться в знаке данного алфавита.
К. Шеннон ввел величину, которую назвал относительной избыточностью языка:
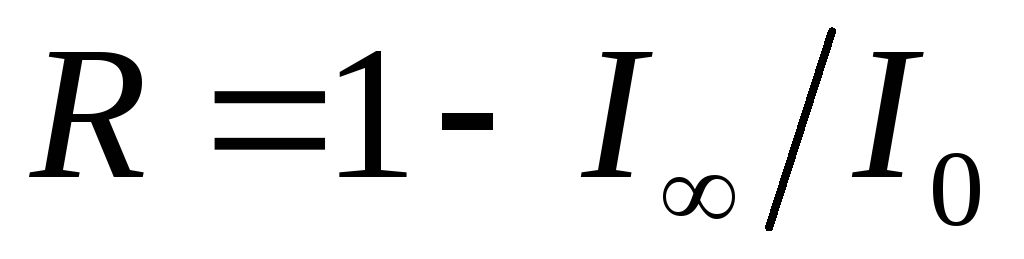 . (6.2)
. (6.2)
Избыточность является мерой бесполезно совершаемых альтернативных выборов при чтении текста. Эта величина показывает, какую долю лишней информации содержат тексты на данном языке; лишней в том смысле, что она определяется структурой самого языка и, следовательно, может быть восстановлена без явного указания в буквенном виде.
Исследования Шеннона для английского языка дали значения 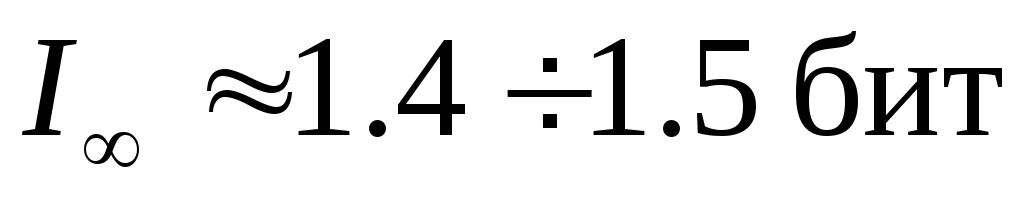 ,
,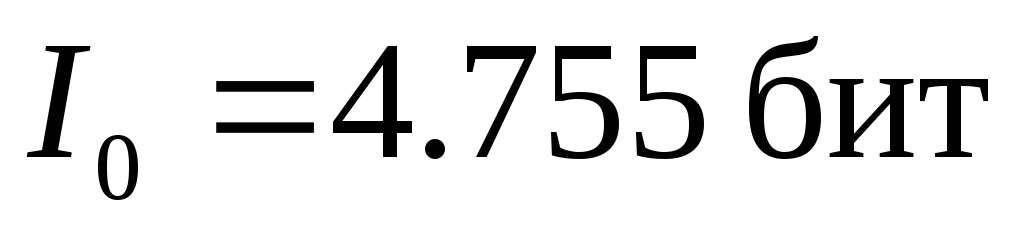 , откуда для избыточности получилось
, откуда для избыточности получилось
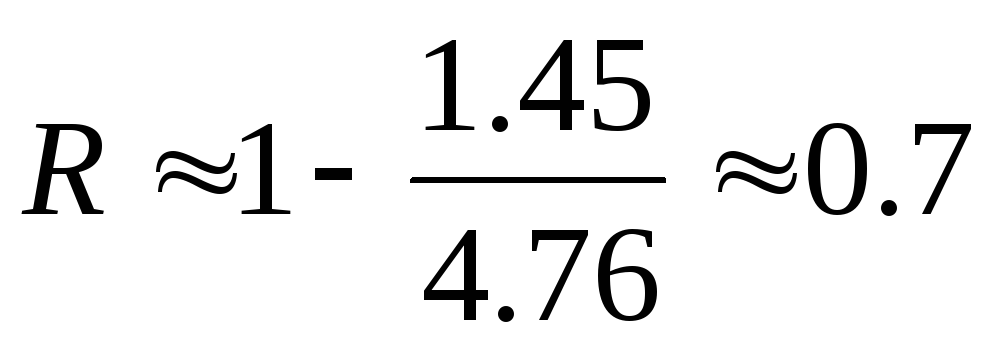 .
.
Подобные оценки показывают, что и для других европейских языков, в том числе для русского языка, избыточность составляет 60–70. Это означает, что в принципе возможно почти трехкратное сокращение текстов без ущерба для их содержательной стороны и выразительности. Например, телеграфные тексты делаются короче за счет отбрасывания союзов и предлогов без ущерба для смысла. В телеграфных текстах используются однозначно интерпретируемые сокращения «ЗПТ» и «ТЧК» вместо полных слов (эти сокращения приходится использовать, поскольку знаки «.» и «,» не входят в телеграфный алфавит). Однако такое «экономичное» представление слов снижает разборчивость языка, уменьшает возможность понимания речи при наличии шума (а это одна из проблем передачи информации по линиям связи). Также сокращения снижают возможность локализации и исправления ошибки при ее возникновении.
Отметим, что избыточность языка имеет полезные функции. Избыточность есть определенная страховка и гарантия разборчивости сообщений (текстов). Избыточность позволяет восстановить текст, даже если он содержит большое число ошибок или неполон (например, при отгадывании кроссвордов, при игре «Поле чудес»).
- http://spravochnick.ru/informatika/kodirovanie_informacii/yazyk_i_alfavit_predstavleniya_informacii/
- http://poisk-ru.ru/s50774t1.html
- http://pptcloud.ru/informatika/yazyk-i-informatsiya-alfavit-bukva-slovo-v-yazyke-kodirovanie
- http://dic.academic.ru/dic.nsf/ruwiki/1278432
- http://xn----7sbbfb7a7aej.xn--p1ai/informatika_kabinet/inf_prozes/inf_prozes_05.html
- http://studfiles.net/preview/2041886/page:12/